
Version [90875]
Dies ist eine alte Version von CIPythonBA erstellt von haeuser am 2018-08-28 13:42:44.
Computational Intelligence in Python
Diese Seite beschreibt die Inhalte des Tutoriums "Tutorium Python Programmierung (Bachelorstudiengang)". Das Ziel des Tutoriums ist es, eine Einfürhrung in Python zu geben, sowie die gezeigten Programmbeispiele in eigenen Übungen zu festigen. Des Weiteren werden verschiedene Methoden zur Klassifizierung und dem einfachste Neuronale Netz vermittelt bzw. gefestigt. Fachübergreifende Kenntnisse wie z.B. die Visualisierung in Python werden ebenfalls vermittelt.
Um den Inhalten folgen zu können, werden geringe Grundkenntnisse in Computational Intelligence / Mustererkennung vorrausgesetzt.
Die Vorbereitung
Der erste Termin handelte von den Grundlagen der Programmierung in Python. Anfgefangen mit der Installation der Entwicklungsumgebung, Erstellung einer Projektes und den Allgemeinen Programmiergrundlagen. Zu den Allgemeinen Programmiergrundlagen gehören die Verwendung von Variablen, Verzweigungen, Schleifen, Listen & andere Datenstrukturen, sowie Exception Handling. Im zweiten Termin setzten wir uns mit dem Multithreading und Multiprocessing auseinanden. Hierbei fanden wir herraus das Python mehrere Threads dennoch nur auf einem Prozessorkern laufen lässt. Dadurch haben wir uns verschiedene Multiprocessing Beispiele angeschaut, weil diese auf meheren Prozessorkernen aufgeteilt werden und somit die von uns gewünschte Synchronität, sowie eine schnellere Verarbeitung bereitstellt. Hierbei haben wir herrausgefunden, dass das Pool Mutlithreading die einfachste und für uns beste Methode war um an unser Ziel zu kommen.
Die Folien und Beispieldaten zu den Grundlagen sowie Multiprocessing können Sie hier herunterladen: Vorlesung 1 & 2 mit Aufgaben
Visualisierung
In der dritten Vorlesung beschäftigten wir uns mit der Visualisierung von Daten von Python, mit der Bibliothek "matplotlib". Hierbei behandelten wir diverse Diagrammtypen und der Konfiguration der Achsen, Beschriftungen und Legenden.

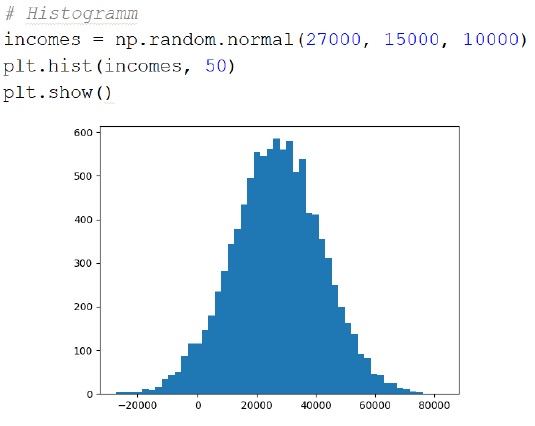
Die Folien zur Visualisierung und kNN können Sie hier herunterladen: Vorlesung 3
Klassifizierungen
k-Nearest Neighbors (KNN)
Als ersten Algorithmus lernten wir den k-Nearest Neighbors (KNN) kennen, welchen Herr Gerlach ausführlich behandelt hat. Kurz gesagt dient dieser Algorithmus als Klassifikationsverfahren, unter der Berücksichtigung der k nächsten Nachbarn. Weitere Details finden Sie auf: Tutorium Python - Master
k-Means
Der k-Means ist ein weitere Klassifizierungsalgorithmus zu Clusteranalyse. Im Gegensatz zu dem KNN, haben die Datensätze noch keine Klassenzuteilung. Dem Algorithmus erhält die Datensätze und wir geben ihm die Anzahl der Gruppen/Cluster mit, anhand desses weist er den Datensätze Gruppen zu. Für diese Zuteilung wird meistens der Lloyd-Algorithmus verwendet, welcher aus 3 Schritten besteht.
- Initialisierung der k zufälligen Mittelwerte
- Zuordnung der Datenpunkte zu einem Cluster
- Hierbei wird die euklidische Distanz von jedem Punkt zu jedem Cluster gebildet
- Der Punkt wird dem Cluster zugewiesen, zu welchem die Distanz am geringsten ist
- Berechnen der Mittelpunkte des Clusters
- Schritt 2 & 3 werden wiederholt bis sich die Mittelpunkte nicht mehr ändern
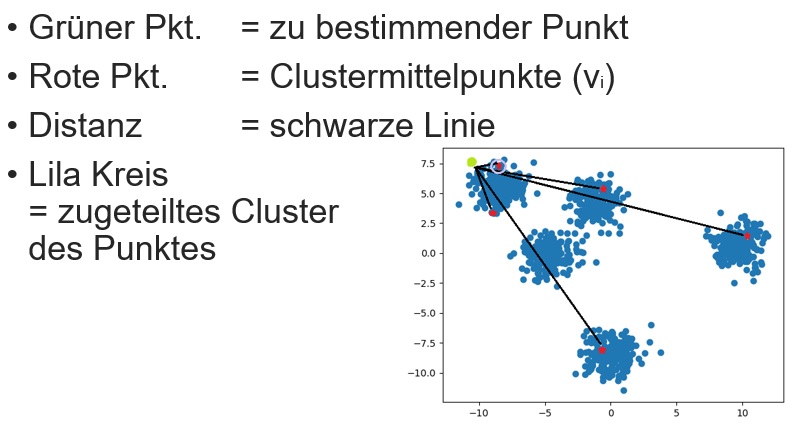
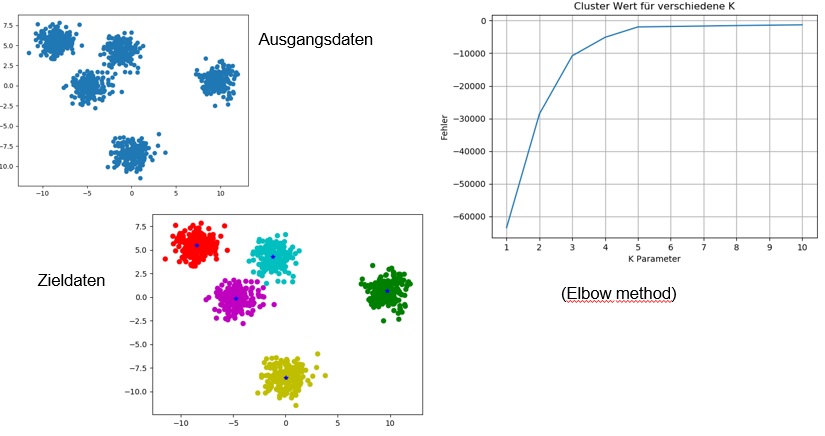
Anwendungsbeispiele
In der Vorlesung haben wir zum einen eine Eigenimplementierung vorgenommen, aber auch das Paket sklearn an dem Beispiel der Bildfarben-Skalierung. Hierbei haben wir das Bild eingelesen und in ein mehr dimensionales Array konvertiert, anhand der X & Y Werte sowie der RGB Farbwerte. Dem Algorithmus wird das dieses X & Y Farbarray übergeben und die Anzahl der Farben, auf welche es herunter skaliert werden soll.
Fuzzy k-Means
Der Fuzzy k-Means ist eine Erweitung des k-Means, wobei jeder Datenpunkt nicht einem einzeln Cluster zugeordnet wird, sondern eine gewisse Prozentzuorndnung zu jedem Cluster erhält. Die Summer der prozentualen Zuordnung ergibt 100%. Für diese Zuordnungen wird eine Zuordnungsmatrix benötigt / erstellt. Noch einer Erweiterung ist die zusätzliche Anpassungvariable (Fuzzyfier), welche auch als Verschleifungsgrad bezeichnet wird. Diese dient für die Schärfe- / Genauigkeitseinstellung der Clusterung. Wird dieser >2 gewählt erfolgt eine sehr unscharfe Clusterung. Wird eine sehr scharfe / genauer Clusterung gewünscht, sollte der Fuzzyfier zwischen 1-2 gewählt werden.Die Folien zum k-Means und Fuzzy k-Means können Sie hier herunterladen: Vorlesung 4.2
Support Vektor Maschiene
Weiteres folgtNoch mögliche Vorlesungspunkte in kommenden Semestern
- Random Forest
- Vertiefende Beispiele Neuronale Netzte (z.B. Bild Unterscheidung Katze/Hund)
- Vertiefende Beispiele SVM