
Version [91652]
Dies ist eine alte Version von Ensemble Vergleiche erstellt von Tobias Dietz am 2018-10-01 22:19:45.
Grundlage der Vergleiche
"Für die Biosignaldaten werden die gleichen Vergleiche angesetzt wie für das vorherige Problem. Bei dem Datensatz handelt es sich um EEG- (Elektroenzephalogramm) Daten. Diese wurden in einer Studie zur Ermittlung von Müdigkeit während des Autofahrens erhoben. Die Studie wurde im Fahrsimulationslabor der Hochschule Schmalkalden im Januar 2018 durchgeführt und schloss 25 Probanden ein. Die Müdigkeit der Probanden wird durch den sogenannten KSS- Wert (Karolinska-Schläfrigkeits-Skala) beschrieben. Dieser Wert ist eine subjektive Selbsteinschätzung des Fahrers auf einer diskreten Skala zwischen 1 und 9, wobei 1 „äußerst wach“ und 9 „sehr schläfrig, große Mühe wach zu bleiben“ bedeutet. Der KSS-Wert wurde alle 5 Minuten vom Fahrer mündlich per Mikrofon mitgeteilt. Er gilt in der Forschung als relativ zuverlässig, da keiner die Müdigkeit einer Person so gut einschätzen kann, wie die Personen selbst. Eine Vernünftige aber fragwürdige Sache.Folgende Kanäle wurden zur Merkmalsextraktion verwendet: FP1, FP2, C3, C4, O1, O2. Nähere Erläuterungen zu diesen und den folgenden Technischen Daten sind bei der Bachelorarbeit „Konzeption und Durchführung einer Nachtfahrtsimulationsstudie zur objektiven Hypovigilanzevaluation“ von Marc-Philipp Tews zu finden. Aus den Kanälen wurden 102 Spektralmerkmale gewonnen, die das dynamische Verhalten der EEG-Signale grob charakterisieren. Die Anzahl der Merkmale wurde so gewählt, dass sie der Anzahl des vorherigen Datensatzes (Kap. 3.1) möglichst ähnlich ist. Alle Merkmale sind Gleitkommazahlen. Der Datensatz beinhaltete 62.972 Merkmalsvektoren, wurde allerdings, um ihn besser mit dem Census-Datensatz vergleichen zu können, auf 45.214 Merkmalsvektoren verkürzt. Hierfür wurden alle Werte unter einem KSS von 6,9747 dem wachen Zustand zugeordnet und bekamen den Zielwert -1. Alle Werte ab einem KSS von 8,1509 wurden dem müden Zustand zugeordnet und bekamen den Zielwert 1. Alle Daten mit KSS Werten zwischen den beiden genannten Schwellwerten wurden von der Untersuchung ausgeschlossen." [1]
Vergleich zwischen den Ensemble Methoden

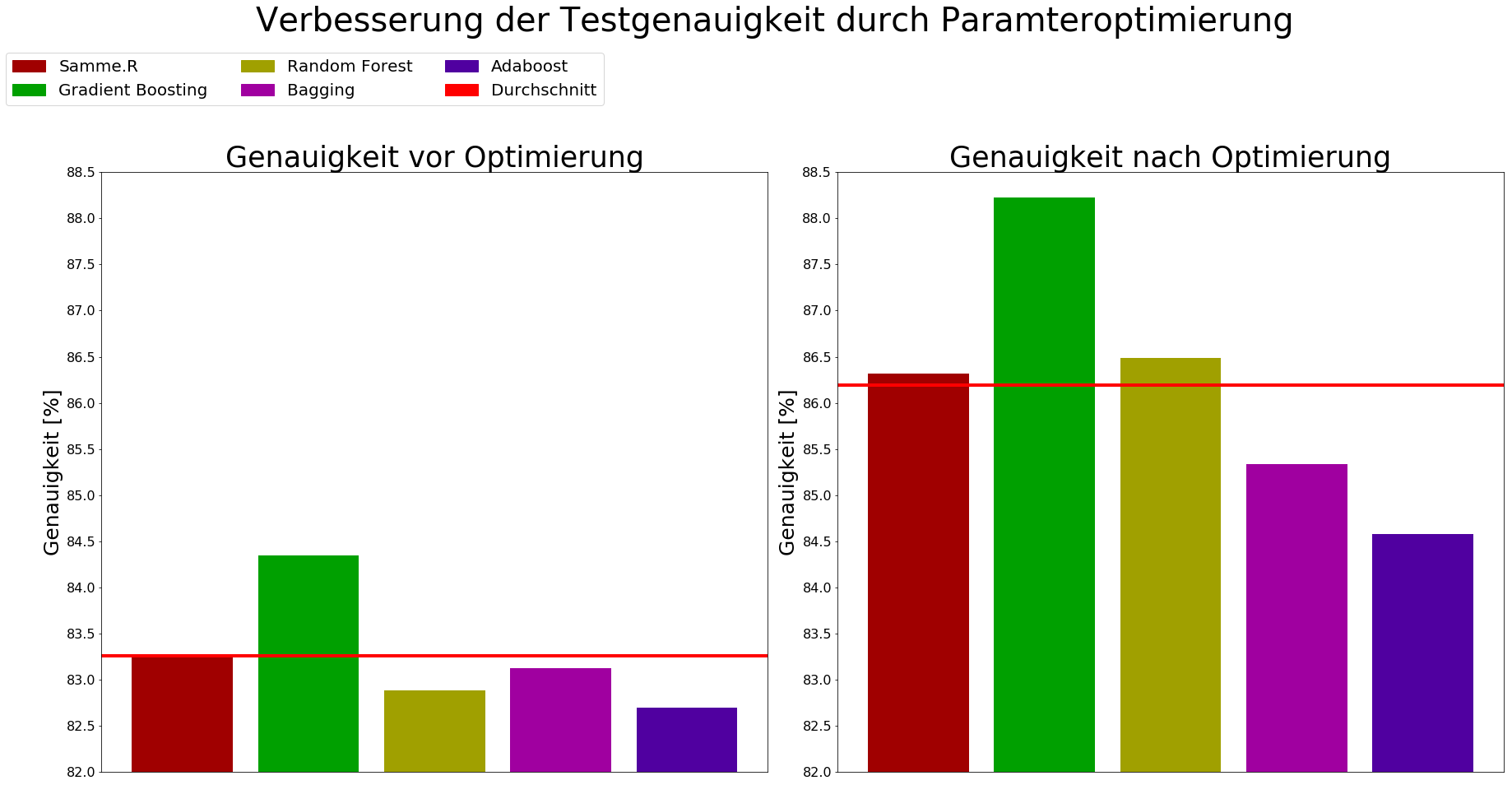
- Die y-Achse zeigt die Genauigkeit der Methoden in % an. De Skala geht von 82 % - 88,5 %.
- Die rote Linie zeigt jeweils den Durchschnitt der fünf Algorithmen an.
- Gradient Boosting erreicht mit 88,2 % und einer Standardabweichung von 0,33 % die mit Abstand höchste Genauigkeit.
- Random Forest erreicht mit 86,4% und einer Standardabweichung von 0,26 % und erreicht damit den zweiten Platz.

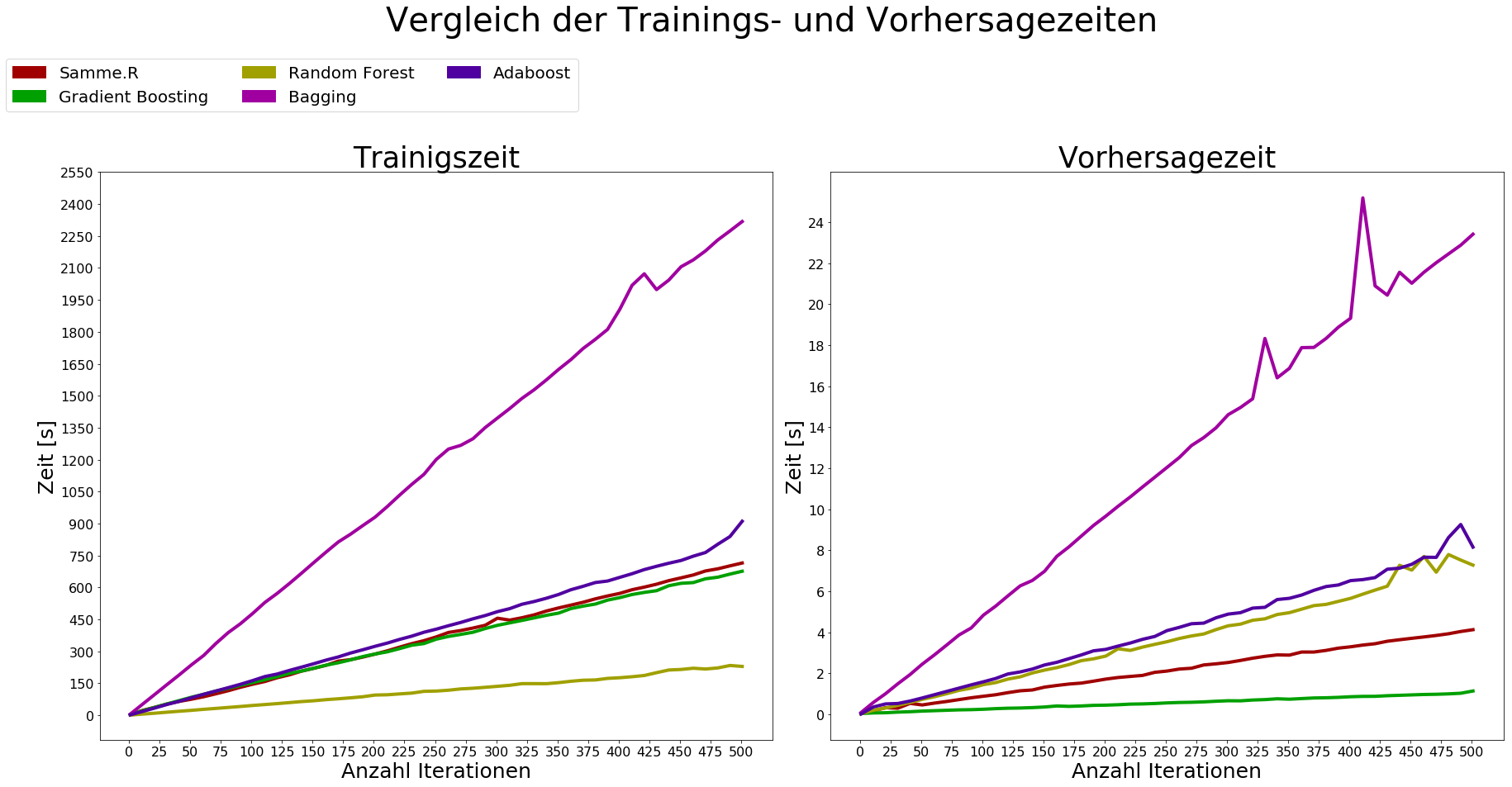
Die y-Achse zeigt die Zeit, welche die jeweilige Methode benötigt hat. Die x-Achse zeigt die Anzahl an Iterationen.
Somit wird verglichen wie sich die Trainings- und Vorhersagezeit durch eine steigende Anzahl an Iterationen erhöht.
Vergleich mit SVM und OLVQ
Literatur
Die Graphiken stammen aus:[1]Dietz T. (2018): Bachelorarbeit “Automatisches rechnerbasiertes Lernen mit Ensemble-Methoden ”, Hochschule Schmalkalden
Die Arbeit enthält auch eine genauer Erläuterung der Ergebnisse, sowie weitere Informationen-
| File | Last modified | Size |
|---|---|---|
| Train_pred_time.png | 2023-10-06 18:36 | 146Kb |
| Vor_Nach_Optimierung.png | 2023-10-06 18:36 | 65Kb |
{kind=link}
{kind=link}