
Betriebssysteme (Betriebssystemtheorie) - Kapitel 7 - Speicherverwaltung
Inhalte von Dr. E. Nadobnyh
7.1 Einführung
Aufgaben der Speicherverwaltung
1) Zuteilung (Allokation) und Freigabe von Speicherbereichen für mehrere Adressräume.
2) Die Abbildung der logischen Adressen auf die physische Adresse.
3) Führung einer Übersicht über freie und belegte Teile des Arbeitsspeichers.
4) Speicherbereinigung und Speicherverdichtung.
5) Auslagerung von Speicherbereichen auf einen Sekundärspeicher.
6) Speicherschutz der Adressräume von unbefugten Speicherzugriffen anderer Prozesse.
Grundbegriffe
1) Eine logische Adresse (Programmadresse) wird von einem Prozess generiert und von der CPU verwendet. Sie ist z.B. der Inhalt des Zeigers.
2) Eine physische Adresse (Speicheradresse) wird beim Speicherzugriff verwendet.
Varianten der Speicherabbildung
1) Mit der vollständigen oder unvollständigen Belegung.
Eine vollständige (komplette) Belegung findet statt, wenn das gesamte Programm in den Speicher geladen wird.
2) Mit der kontinuierlichen oder diskontinuierlichen Belegung.
Eine kontinuierliche Belegung findet statt, wenn verschiedene Teile des Programms zusammenhängend im Speicher platziert werden.
3) Mit oder ohne Auslagerung.
Eine Auslagerung ist eine regelmäßige Speicherung des Programms vom Hauptspeicher in Sekundärspeicher, z.B. auf die Festplatte und zurück.
⇒ Demo 1
Überblick
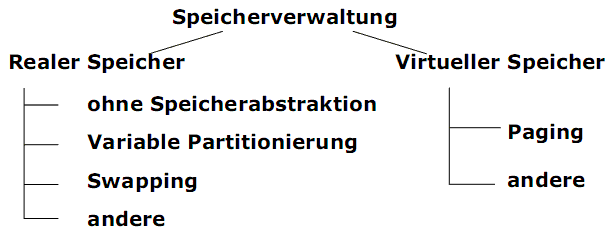
1) Realer Speicher: Ein Prozess kann nur dann laufen, wenn sich sein Adressraum vollständig im Speicher befindet.
2) Virtueller Speicher: Ein Prozess kann auch dann laufen, wenn sich nur ein Teil seines Adressraums im Speicher befindet.
7.2. Realer Speicher
Systeme ohne Speicherabstraktion
Im Hauptspeicher steht das Betriebssystem und ein einziges Anwenderprogramm.
Besonderheiten:
1) Logische und physische Adressen sind gleich.
2) Physische Adressen können zur Übersetzungszeit schon bekannt sein.
3) Es gibt keinen Speicherschutz. Ein Fehler im Anwendungsprogramm kann das Betriebssystem aushebeln, wenn es sich nicht im ROM befindet.
4) Diese Technik ist für Monoprogrammierung (Singletasking, Einprogrammbetrieb) geeignet und wird heute höchstens in einfachen eingebetteten Systemen verwendet. Frühes Beispiel: MS-DOS.
Variable Partitionierung
Definition:
Variable Partitionierung (Partitionierung variabler Größe) ist eine dynamische Aufteilung des Speichers in eine variable Anzahl von Bereichen variabler Größe.
Sachverhalt:
1) Speichersystem bedient die beliebige Reihenfolge von Reservierungen und Freigaben.
2) Reservierungen fordern Bereiche mit verschiedenen Größen.
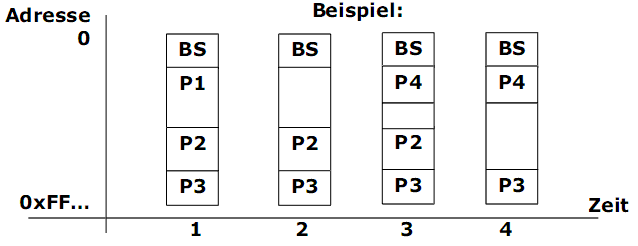
Legende: P1, P2, P3, P4 – Prozesse.
Zeitpunkte:
- Drei Prozesse am Laufen.
- Prozess P1 endet. Freigabe. Lücke entsteht.
- Prozess P4 kommt. Reservierung. Neue Lücke entsteht.
- Prozess P2 endet. Rekombination von zwei Lücken
Dynamische Relokation
Bei der Partitionierung wird die Anfangsadresse eines Programms erst zur Ladezeit bekannt. Damit wird auch die Adresstransformation erst zur Ladezeit möglich.
Dynamische Relokation ist eine Technik für die Speicherabbildung zur Laufzeit:
1) Der Adressraum jedes Prozesses wird komplett in den Speicher geladen.
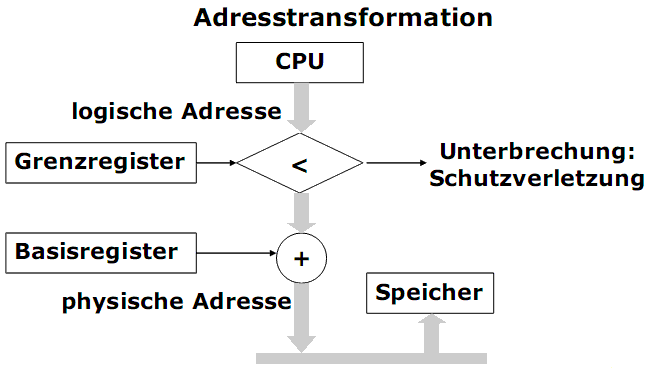
2) Die Adresstransformation findet bei jedem Speicherzugriff statt. Zu der logischen Adresse wird der Inhalt eines Basisregisters (oder Relokationsregisters) addiert. Das Basisregister enthält die physikalische Partitionsstartadresse.
Das Programm kann auch zur Laufzeit mit logischenAdressen arbeiten.
3) Für die korrekte Speicherabbildung ist der Zugriffsschutz notwendig. Bei jedem Speicherzugriff wird überprüft, ob die Adresse
innerhalb des Adressraums liegt. Dazu dient ein Grenzregister (Schutz-Register, Limitregister), das die Größe des Adressraums enthält.
4) Beim Prozesswechsel werden beide Register umgesetzt.
Bemerkungen:
1) Dynamische Relokation bietet eine Abstraktion vom physischen Speicher. Die Speicherverwaltung ist für den Programmierer transparent.
3) Eine frühere Lösung war die statische Relokation. Dabei werden alle Adressen im Programm reloziert, wenn das Programm in den Speicher geladen wird.
Swapping
Grungidee: Wenn ein Prozess im Moment keine Rechenzeit benötigt, dann wird sein Adressraum komplett in Sekundärspeicher ausgelagert.
Verwendung:
1) Diese Technik wurde in Systemen ohne Speicherabstraktion verwendet, um mehrere Programme gleichzeitig auszuführen.
2) Swapping lässt sich mit variabler Partitionierung kombinieren:
- Bei Speichermangel werden Prozesse ausgelagert.
- Die freigewordenen Speicherbereiche werden für neue oder für ausgelagerte Prozesse genutzt.
- Die Gesamtzahl der gestarteten Prozesse entspricht nämlich der Summe der ausgelagerten und nicht ausgelagerten Prozesse.
- Swapping wurde bei älteren Unix-Systemen eingesetzt.
7.3.Freispeicherverwaltung
Grundidee
Das Ziel der Verwaltung des freien Speichers (dynamische Speicherbereitstellung) ist die effiziente Nutzung des realen Speichers. Dabei sollen die Zeit der Speicherzuteilung und die Fragmentierung minimiert werden.
Eine externe Fragmentierung (Zerstückelung, Verschnitt, Zersplitterung) ist ein Speicherzustand mit den schlecht nutzbaren Lücken. Im Laufe der Zeit entstehen überall im Speicher freie Bereiche, die teilweise zu klein sind, um Adressräume hineinladen zu können. Dabei kann eine neue Reservierung nicht erfüllt werden, obwohl insgesamt genügend Speicher frei ist.
Eine interne Fragmentierung ist der ungenutzte Teil des zugeteilten Speicherbereiches.
Einige Techniken
1) Speicherverdichtung (Kompaktierung, Verschiebung) ist eine Technik, bei der alle belegten Bereiche umkopiert werden, so dass nur eine große Lücke vorhanden ist.
Nachteil: Diese Technik ist zeitfressend und wird normalerweise nicht eingesetzt.
2) Abrundung: Wenn der Rest der Lücke zu klein ist, dann wird ganze Lücke reserviert.
Vorteil: Im Speicher entstehen keine kleine Lücken
Nachteil: Interne Fragmentierung.
3) Speicherbereinigung (Garbage Collection): Freigabe und aufwendige Rekombinationen werden automatisch zu einem späteren Zeitpunkt durchgeführt.
Vorteil: Optimalerweise findet eine Speicherbereinigung immer in Leerlaufphasen statt.
Belegungsstrategien
Belegungsstrategien (Allokations-Algorithmen) sind Algorithmen, die nach einer passenden Lücke im fragmentierten Speicher suchen.
1) Sequentielle Belegungsstrategien, welche eine einzige Liste oder andere Datenstruktur für alle Lücken führen.
2) Strategien mit festen Größenklassen (separierten Freilisten), welche mehrere Listen für verschiedene Lückengrößen führen.
Sequentielle Belegungsstrategien
| Name | Die Suche beginnt | Gesuchte Lücke | Erzeugte Lücken |
| First Fit/ Last Fit | am Speicheranfang | erste/ letzte | Kleine Lücken entsteh- en am Anfang/am Ende des Speichers |
| Next Fit | am letzten allokierten Bereich. | erste | Kleine Lücken sind gleichmäßig überall. |
| Best Fit/ Worst Fit | am Speicheranfang | kleinste/ größte | Tendiert zum Erzeugen kleiner/großer Lücken |
Vorteile: Es gibt keine innere Fragmentierung.
Nachteile:
- Wesentliche externe Fragmentierung.
- Sequentielle Algorithmen sind langsam, besonders Best Fit und Worst Fit.
Sequentielle Belegungsstrategien. Beispiel
1) Ausgangssituation(in MB):
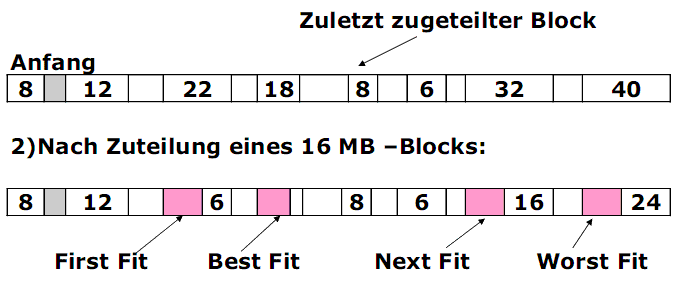
Strategien mit separierten Freilisten
1) Quick Fit führt mehrere getrennte Listen für verschiedene Lückengrößen. Diese Strategie ist sinnvoll, wenn alle Anforderungen von gleichen oder bestimmten häufig benötigten Größen sind.
Vorteile:
- Diese Strategie ist extrem schnell bei der Reservierung.
- Keine Fragmentierung.
Nachteil:
Rekombination ist aufwendig, weil alle Löcher nicht nach der Adresse, sondern nach der Größe sortiert sind.
2) Buddy–Algorithmus verteilt den Speicher in Größen von Zweierpotenzen. Alle Anforderungen müssen also auf die nächste Zweierpotenz aufgerundet werden.
Vorteil:
Diese Strategie ist extrem schnell bei der Reservierung und bei der Rekombination.
Nachteil:
Interne Fragmentierung ist erheblich (bis 25%).
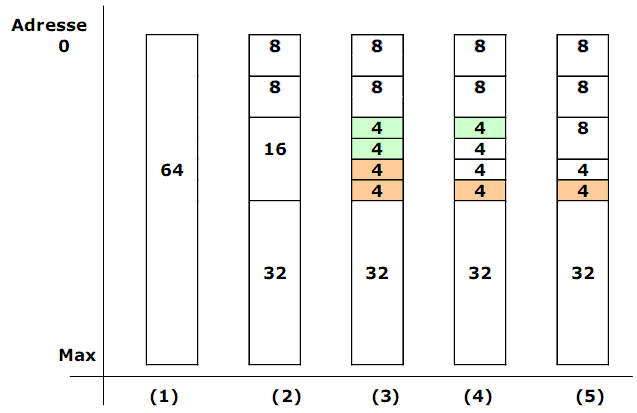
Buddy-Algorithmus
Verwaltungsdaten:
1) Der Speicher wird in Größen von Zweierpotenzen verteilt. Jede Anforderung muss auf die nächste Zweierpotenz 2k aufgerundet werden.
Eine Anforderung in 280 Bytes wird z.B. auf 29 = 512 Bytes aufgerundet.
2) Für jede Speichergröße wird eine eigene Liste verwendet.Es gibt Listen für die folgende Blockgrößen:
20 , 21 , 22 … 2S Byte, wo 2S - Speichergröße ist.
Anfangs sind alle Listen leer, nur in der 2S -Liste ist ein einziger Block (der gesamte Speicher).
3) Jeder Block wird markiert: reserviert oder frei.
Speicheranforderung:
1) Ein Block 2k wird aus der entsprechenden Liste zugeteilt.
2) Ist kein Block der gewünschten Größe frei, werden schrittweise die höheren Blockgrößen geprüft, bis ein freier Block gefunden wird.
3) Wird kein Block gefunden, wird die Speicheranforderung abgelehnt.
4) Der gefundene Block wird durch iterierte Halbierung soweit zerlegt, bis ein Block der benötigten Größe 2k entsteht.
Bei jeder Halbierung entstehen zwei doppelt kleinere Blöcke der gleichen Größe (Buddies, Kumpel).
Freigabe:
1) Bei jeder Freigabe muss die Rekombination mit den benachbarten Blöcken derselben Größe geprüft werden.
Zwei benachbarte Blöcke der Große 2k mit Adressen x und y sind Buddies, wenn die folgende Bedingung zutrifft:
y == x XOR 2k
Bei der Rekombination entsteht ein Block der doppelten Größe 2k+1.
2) Im Erfolgsfall muss auch die Rekombination der Blöcke mit höherer Größe iteriert geprüft werden.
Beispiel:
(1) Anfänglich besteht der Speicher aus einem kontinuierlichen Block 64 K.
(2) Zwei Anforderungen 8 K fallen an. Der Block 64 K wird dreimal halbiert. Beide Anforderungen werden erfüllt.
(3) Vier Anforderungen 4 K fallen an. Der Block 16 K wird zweimal halbiert und alle Anforderungen werden erfüllt.
(4) Zweite und dritte Blöcke 4 K werden freigegeben. Bei der Rekombinations-Prüfung wird kein Buddy gefunden.
(5) Der erste Block 4 K wird freigegeben. Bei der Prüfung werden zwei Buddies gefunden und rekombiniert.
Belegungsstrategien. Fazit
Keine der Strategien ist ideal, da praktische Situationen sehr unterschiedlich sind.
Zum Beispiel, es sei gegeben:
- zwei Lücken 1300 und 1200 Bytes,
- drei Aufträge 1000, 1100 und 250 Bytes.
Belegung und neu markierte Lücken:
| Strategie | 1.Auftrag | 2.Auftrag | 1.Auftrag |
| First Fit | 1300-1000= 300 | 1200-1100= 100 | 300-250= 50 |
| Best Fit | 1200-1000= 200 | 1300-1100= 200 | Reservierung abgelehnt |
Verwendung der Freispeicherverwaltung
1) für Multitasking in einfachen Systemen, z.B.:
- Belegung mit variablen Partitionen
- Swapping;
2) im Betriebssystem selbst, z.B.:
- für innere Speicherverwaltung
- Speicherzuordnung für Treiber;
3) in Anwendungsprogrammen, z.B.:
- Heap Management.
⇒ Demo 2
7.4. Virtueller Speicher
Definition
Virtueller Speicher ist eine Speichertechnik, bei welcher Adressräume vom Hauptspeicher vollkommen abstrahiert werden.
Die Grundidee ist eine Erweiterung der Speicherkapazität unter Zuhilfenahme externen Sekundärspeicher.
Funktionsprinzip:
1) Im Hauptspeicher befinden sich gleichzeitig nur die Teile von mehreren Adressräumen.
2) Restliche Teile befinden sich auf dem Sekundärspeicher (Hintergrundspeicher, z.B. Festplatte).
3) Die Teile des Adressraums werden zur Laufzeit nur nach Bedarf in den Hauptspeicher eingelagert und auch auslagert.
Eigenschaften
1) Der logische Adressraum jedes Prozesses ist nur durch die Adressbreite begrenzt.
Beispiel: Bei der 32-Bit Adressbreite ist die Adressraumgröße 232 = 4GB. Der Intervall der logischen Adressen ist von 0x00000000 bis 0xFFFFFFFF.
2) Jeder Prozess teilt den Adressraum höchstens mit dem Betriebssystem selbst.
Beispiel: Unter Windows NT wird nur ein 2 GB großen Raum für den Benutzerprozess verteilt.
3) Der Adressraum eines Prozesses kann größer als der real vorhandene Speicher sein. Solche Prozesse werden als „große Prozesse“ bezeichnet.
Beispiel: Die Hauptspeichergröße kann 0,5 GB sein und dann 2>0,5.
⇒ Demo 3.
4) Der logische Adressraum wird als virtueller Adressraum und die logische Adresse als virtuelle Adresse bezeichnet.
5) Ein Programmierer erhält die Illusion, dass er einen Speicher besitzt, welcher größer als Hauptspeicher und so schnell wie Hauptspeicher ist. Dieser illusorische Speicher wird als virtueller Speicher bezeichnet.
6) Nicht benötige Teile können manchmal nie eingelagert werden. Beispiele:
- Die Ausnahmebehandlungsfunktionen werden nur selten aufgerufen.
- Die statisch reservierte Felder werden nicht bei jeder Ausführung vollständig verwendet.
8) Jeder Prozess ist gegen Fehlzugriffe aller anderen Prozesse geschützt.
Bedingungen
Für die Realisierung des virtuellen Speichers sind folgende Voraussetzungen nötig:
1) Programme verfügen über den so genannten Lokalitätseffekt (Lokalitätseigenschaft).
2) Das System verfügt über die passende Speicherhierarchie.
3) Die Adresstransformation muss durch die speziellen Hardware unterstützt werden, z.B. MMU, TLB. Sonst wird die Adresstransformation zu langsam.
Lokalität von Programmen
Definition:
1) Räumliche Lokalität. Wird auf eine bestimmte Adresse im Hauptspeicher zugegriffen, so erfolgt der nachfolgende Zugriff mit großer Wahrscheinlichkeit in der Nachbarschaft.
2) Zeitliche Lokalität. Wird auf eine bestimmte Adresse im Hauptspeicher zugegriffen, wird in naher Zukunft mit großer Wahrscheinlichkeit wieder darauf zugegriffen.
Beispiel:
for(int i=0; i<100; i++) s + =a[i];
Zugriffe auf Elemente des Feldes a[i].
Fazit: Wegen Lokalität wird in einem gewissen Zeitabschnitt
nie der gesamte Adressraum des Programms benötigt.
Speicherhierarchie
Eine Speicherhierarchie ist eine koordinierte Nutzung von verschiedenen Speicher.
Funktionsprinzip:
1) Die verschiedenen Speicherarten werden in Ebenen aufgeteilt (z.B. Register, Cache, Hauptspeicher und Festplatte).
2) Jede Ebene ist schneller, kleiner und teurer (Preis pro Byte) als die Ebene darunter.
3) Alle Daten einer Ebene sind auch in der Ebene darunter enthalten.
4) Daten werden nur zwischen benachbarten Ebenen übertragen.
Das Ziel einer Speicherhierarchie ist es, mit dem großen Speicherbereich einer unteren Ebene zu arbeiten und dieses mit der Geschwindigkeit einer oberen Ebene.
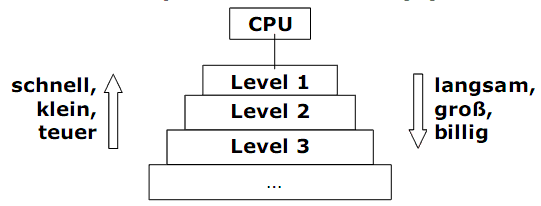
Zwei bekannte Techniken:
1) Cach –Speicher verwendet zwei Levels: Cache und Hauptspeicher.
2) Virtueller Speicher verwendet zwei Levels: Hauptspeicher und Sekundärspeicher (Festplatte).
Bemerkung: Der sekundäre Speicher wird nicht nur für die Speicherhierarchie, sondern auch zur Datenhaltung (Dateisystem) verwendet.
Adresstransformation
1) Die logische Adresse in den Befehlen bleibt auch nach dem Laden in den Hauptspeicher unverändert erhalten. Der Prozessor arbeitet mit logischen (virtuellen) Adressen.
2) Die Adresstransformation findet bei jedem Speicherzugriff statt.
3) Zur Adresstransformation wird eine Kombination aus Hard- und Software eingesetzt:
- MMU (memory management unit, Speicherverwaltungseinheit) ist eine spezielle Hardware für Adresstransformation. Heute wird die MMU direkt in die CPU integriert.
- Die speziellen Tabellen für die Adresstransformation werden vom Betriebssystem erstellt und aktualisiert.
4) Grundvoraussetzung für die Realisierung ist die Fähigkeit der CPU, einen laufenden Befehl zu unterbrechen und nach erfolgtem Nachladen den begonnenen Befehl vollständig auszuführen.
5) Das Nachladen der Programm- und Datenabschnitte besorgt ein Betriebssystem.
6) Die virtuelle Speichertechnik ist für den Anwender vollkommen transparent. Sowohl das Nachladen von Programm- und Datenabschnitten als auch die Adresstransformation geschieht automatisch.
7) Implementierungen:
- Paging,
- Segmentierung,
- Segmentierung mit Paging.
7.5. Paging
Grundbegriffe
1) Die meisten Systeme mit virtuellem Speicher verwenden eine Technik namens Paging (Seitenadressierung).
2) Dabei werden alle Adressräume und Speicher in Blöcke gleicher Länge (Pages, Frames und Slots) eingeteilt.
3) Der Adressraum jedes Prozesses ist in Seiten (Pages) aufgeteilt. Es besteht keinerlei Bezug zur logischen Struktur des Programms. Eine Seite stellt die Austauscheinheit beim Seitenwechsel dar.
4) Der Hauptspeicher ist in Seitenrahmen (Seitenkacheln, Frames) aufgeteilt.
5) Adressräume von allen beteiligen Prozessen sind auch im Sekundärspeicher (in der Ebene darunter) enthalten und werden hier auf Slots geteilt. Adressräume können in einer speziellen Auslagerungsdatei gespeichert werden, z.B.: C:\pagefile.sys unter Windows.
Eigenschaften
1) Jeder Seite eines Adressraums kann dynamisch ein beliebiger Seitenrahmen des Hauptspeichers zugeordnet werden.
2) Paging hat keine externe Fragmentierung.
3) Keine Suche nach einem "passenden Loch" im Hauptspeicher für eine neu zu ladende Seite ist erforderlich.
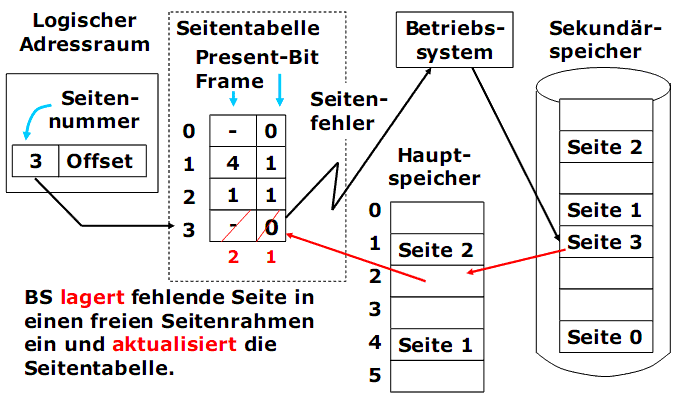
Speicherabbildung
1) Die Speicherabbildung wird mittels einer Seitentabelle verwaltet. Eine Seitentabelle wird für jeden Prozess vom Betriebssystem eingerichtet.
2) Über die Seitentabelle werden alle Seiten des Adressraums auf die Frames abgebildet.
3) Jede Zeile (Eintrag) der Seitentabelle enthält u.a.:
- ein Zustand der Seite, der als ein Present-Bit (valid bit, Gültigkeitsbit) dargestellt wird. Wenn Present=0, befindet sich diese Seite nicht im Hauptspeicher (nicht eingelagert);
- eine Seitenrahmen-Nummer (Frame), wenn die Seite eingelagert ist.
Speicherabbildung. Beispiel
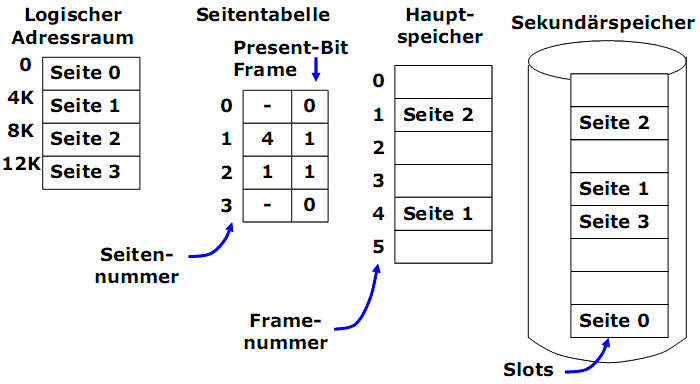
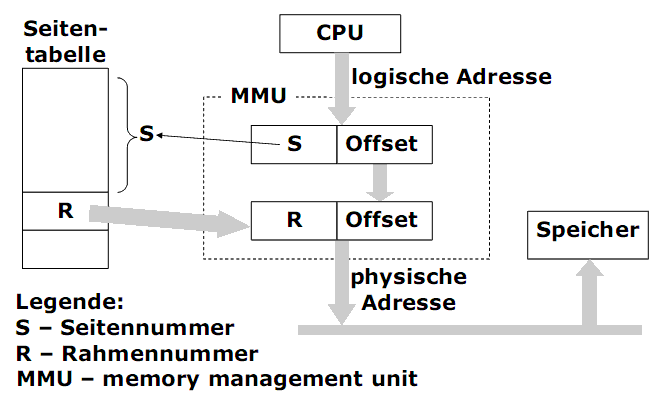
Adresstransformation
1) Compiler, Linker und der Prozessor arbeiten ausschließlich mit logischen (virtuellen) Adressen.
2) Eine logische Adresse ist in einen Offset und eine Seitennummer aufgeteilt:
- Ein Offset (Distanz, Wortadresse) ist eine relative Adresse innerhalb der Seite.
- Eine Seiten-Nummer ist ein Index in der entsprechenden Seitentabelle.
3) Durch diese Aufteilung ist die Seitengröße eine Zweierpotenz, typischerweise: 29 Bytes bis 212 .
Beispiel: 32 Bit-Adressen mit der Seitengröße 212 = 4 KB unter Unix und Windows auf dem PC.

MMU erfüllt die Adresstransformation:
R = Seitentabelle[S]
P = R + Offset
Legende:
S - Seitennummer,
R - Seitenrahmennummer aus der Seitentabelle.
P - physische Adresse,
+ - Konkatenation.
Eigenschaften:
1) Die Seitennummer wird als Index der Seitentabelle benutzt.
2) Der Tabellenzugriff wird durch die MMU beschleunigt.
3) Der Offset ist in der logischen und der physikalischen Adresse identisch.
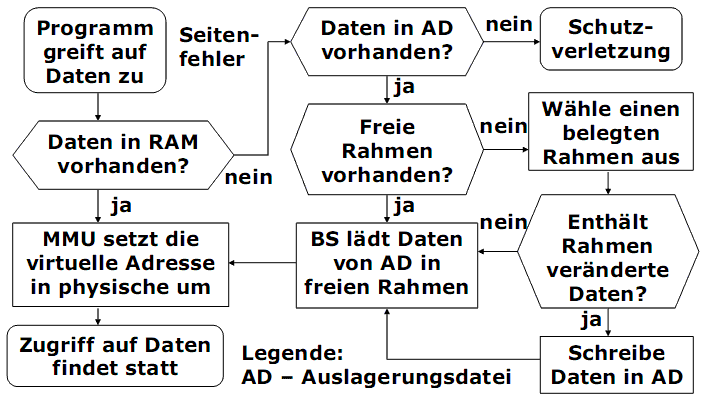
7.6. Seitenfehlerbehandlung
Seitenfehler und Einlagerung
Paging erlaubt die Ausführung von Prozessen, die nicht komplett im Hauptspeicher stehen. Die Seiten eines Prozesses werden erst eingelagert, wenn sie gebraucht werden (nach Bedarf, Demand Paging).
Sachverhalt:
1) Beim Zugriff auf eine nicht eingelagerte Seite (Present=0) wird ein Interrupt ausgelöst, der als Seitenfehler (page fault) bezeichnet wird.
2) Die Instruktion, die den Seitenfehler verursacht hat, wird abgebrochen. Der Prozess wird blockiert.
3) Das Betriebssystem lagert fehlende Seite in einen freien Seitenrahmen ein und aktualisiert die Seitentabelle.
4) Der Prozess-Zustand wird zu „rechenbereit“ geändert.
5) Anschließend wird die Instruktion, die vorher den Seitenfehler verursacht hat, wiederholt werden, diesmal erfolgreich.
Seitenfehler. Ablauf
Seitenfehler. Beispiel
Speicherschutz
1) Bei der Seitenfehlerbehandlung prüft das Betriebssystem, ob die referenzierten Seiten in der Auslagerungsdatei vorhanden sind.
2) Dafür werden interne Tabellen kontrolliert (z.B. PCB, Slot-Nummer, Auslagerungsadresse).
3) Wenn Seiten fehlen, handelt es sich um einen Zugriff auf verbotene Adresse, d.h. Schutzverletzung. Das Betriebssystem kann dem Prozess ein Signal (Fehlermeldung) senden oder ihn abbrechen.
Seitenersetzung
1) Wenn der Hauptspeicher zu knapp wird, muss eine oder mehrere Seiten (Opferseiten) ersetzt werden, um Platz zu schaffen (Seitenersetzung, Verdrängung, Replacement).
2) Nach dem Modell der Speicherhierarchie sind alle Seiten im Sekundärspeicher vorhanden. Einige von ihnen werden auch im Hauptspeicher eingelagert.
Opferseiten, die im Hauptspeicher nicht geändert wurden, brauchen nicht in den Sekundärspeicher zurückgespeichert werden, sondern können sofort durch die neue Seite überschrieben werden. Zeit wird dadurch gespart.
3) Ein typischer Seitentabelleneintrag enthält u.a. das M-Bit (Modified-Bit, Dirty-Bit). Wenn ein Programm in eine Seite schreibt, setzt die Hardware automatisch das M-Bit. Dieses Bit wird benutzt, um eine Seite auszulagern.
7.7. Seitentabellen-Hardware
Problem. Seitentabellengröße
1) Bei einer Adressraumgröße von 4 GB (32 Bit-Adressen) und einer Seitengröße von 4 KB hat der Adressraum über eine Million Seiten (220).
2) Tatsächlicher Bedarf ist nicht so groß, meist wird nur ein kleiner Bruchteil vom Maximum genutzt.
3) Der gesamte Adressraum wird meist vom Compiler in 4 Bereiche aufgeteilt: Stack, Code, Data und Heap.
4) Moderne Systeme tendieren zu großen Adressräumen, von denen nur kleine, aber nicht zusammenhängende Teilbereiche genutzt werden.
5) Wenn eine Seitentabelle groß ist und nicht alle ihre Teile verwendet werden, entsteht die Speicherplatzverschwendung.
6) Beim Multitasking benötigt jeder Prozess eine Seitentabelle.
Lösungen. Überblick
Die Seitentabelle kann extrem groß werden und der Zugriff auf die Seitentabellen kann ohne zusätzlicher Seitentabellen-Hardware zu langsam werden.
Es gibt unterschiedliche Formen der Hardwareunterstützung:
1) Seitentabellen im Registersatz.
2) Seitentabellen im Hauptspeicher.
3) Assoziativ-Speicher für Seitentabelleneinträge.
4) Mehrstufige Seitentabellen.
5) Invertierte Seitentabellen.
Seitentabellen in Registersatz
Eine Seitentabelle kann in einem separaten Registersatz angelegt werden.
Diese Form funktioniert nur bei kleinen Seitentabellen, z.B. in PDP-11.
Vorteile:
1) Dies ist die einfachste Form.
2) Für die Seitentabelle werden keine Speicherzugriffe benötigt.
Nachteile:
1) Beim Prozesswechsel muss der ganze Registersatz zwischen CPU und PCB gewechselt werden.
2) Für große Seitentabellen ist diese Form zu teuer.
Seitentabellen im Hauptspeicher
Eine Seitentabelle kann komplett im Hauptspeicher gehalten werden. Die Hardware braucht ein einziges Register Seitentabellenregister, Page-Table-Base-Register, PTBR), das auf den Anfang der Seitentabelle zeigt.
Vorteil:
Beim Prozesswechsel muss nur das Register aktualisiert werden.
Nachteile:
1) Jeder Speicherzugriff dauert die doppelte Zeit. Aus jedem Speicherzugriff werden zwei: der erste auf die Seitentabelle, der zweite auf den Seitenrahmen.
2) Die Seitentabellen unterliegen selbst dem Paging und es können bei einem Hauptspeicherzugriff gleich zwei Seitenfehler auftreten.
Assoziativ-Speicher
1) Ein Assoziativ-Speicher ist normalerweise als superschneller Speicher realisiert. Ein Register besteht aus Schlüssel und Wert.
2) Bei der Eingabe eines Schlüssels S in den Assoziativ-Speicher wird gleichzeitig (parallel) in allen Registern einen Schlüsselvergleich durchgeführt.
3) Das Register, dessen Schlüsselfeld mit S übereinstimmt, liefert den zugehörigen Wert W.
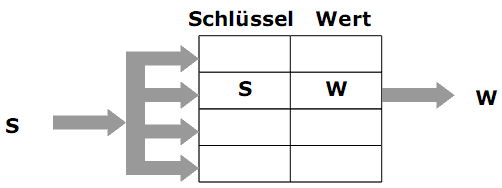
TLB
Um den Zugriff auf die Seitentabelle zu beschleunigen, werden einige Einträge der Seitentabellen im Assoziativ-Speicher (TLB, translation look-aside buffer) gepuffert. TLB ist normalerweise ein Teil der MMU.
Als Schlüssel wird die Seitennummer verwendet, der Wert ist die Rahmennummer.
TLB funktioniert wie ein Cache-Bereich:
1) Falls das TLB den Schlüssel nicht enthält, wird
- die Rahmennummer aus der Seitentabelle ermittelt und
- in den Assoziativspeicher anstelle des am längsten nicht mehr zugegriffenen Schlüssels eingetragen.
2) TLB basiert auf dem Lokalitätseffekt: Programme führen sehr viele Zugriffe auf sehr wenige Seiten.
3) Die Seitennummer wurde nicht als Index verwendet, sondern als ein Eintrag im TLB.
Vorteil:
In der Praxis erzielt man schon beim TLB mit 32 Registern eine Trefferrate von über 90%, d.h. 9 von 10 Hauptspeicherzugriffen können ohne Zugriff auf die Seitentabelle durchgeführt werden.
Nachteil:
Der Prozesswechsel ist aufwändig, weil der TLB in der Regel komplett gelöscht wird.
Mehrstufige Seitentabellen
Sachverhalt:
1) Ein typischer Prozess benutzt von seinem Adressraum N zusammenhängende Bereiche. Zwischen diesen Bereichen können beliebige Lücken auftreten.
2) Die entsprechende Seitentabelle ist nur dünn besetzt.
3) Statt einer einzigen Seitentabelle, die groß und dünn besetzt ist, kann das System N kleineren Seitentabellen verwalten: eine Tabelle pro Bereich.
4) Dann benötigt man noch eine übergeordnete Tabelle (Hauptseitentabelle, Page-Directory) mit N Einträgen, die jeweils auf die untergeordneten Tabellen verweisen. So entsteht eine mehrstufige Seitentabelle (Multilevel Paging).
5) Die Hauptseitentabelle muss zwingend im Speicher gehalten werden.
6) In der Praxis sind zwei- und dreistufige Tabellen zu finden.
Vorteile:
- Seitentabellen können ausgelagert werden.
- Große Teile der Seitentabelle müssen gar nicht definiert werden.
Nachteil:
Die Verwendung von TLB ist hier zwingend notwendig, sonst finden pro CPU-Zugriff insgesamt drei Speicherzugriffe statt.
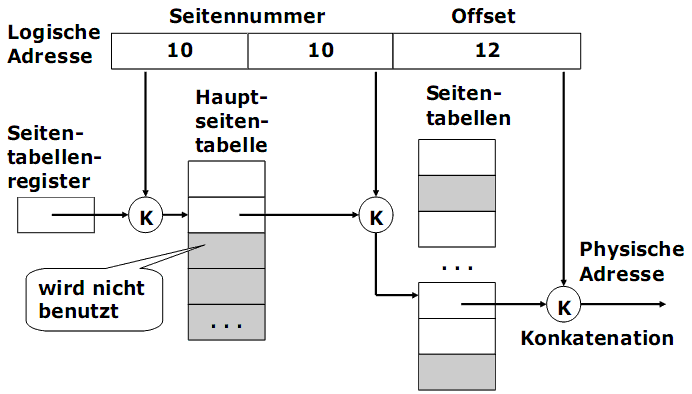
Beispiel. Zweistufige Seitentabellen:
- Die Seitennummer (20 Bit) wird in zwei weitere Teile aufgeteilt:
- Page-Directory-Index (10 Bit) und
- Page-Table-Index (10 Bit).
- Die Adresstransformation besteht aus zwei Schritten und wird hardwaremäßig von MMU unterstützt.
Zweistufige Seitentabelle. Adresstransformation
7.8. Working-Set und Thrashing
Working-Set
Die meisten Prozesse nutzen nicht den gesamten virtuellen Adressraum, sondern nur einen Teil davon. Die Menge der Seiten eines Prozesses, die aktuell genutzt werden, heißt Working-Set (Arbeitsbereich).
Passt das Working-Set nicht in den verfügbaren Speicher, so erzeugt der Prozess viele Seitenfehler. Die Größe eines Working-Set ändert sich im Laufe der Zeit und muss entsprechend angepasst werden.
Beispiel:
Das Working-Set wird in Windows 2000 durch zwei Parameter, die minimale und die maximale Größe bestimmt. Die Default-Werte liegen je nach Hauptspeichergröße zwischen 20 – 50 für das Minimum und 45 – 345 für das Maximum. Stark „pagende“ Prozesse können ihren Working-Set auch erhöhen, aber nur bis maximal 512 Seiten.
Seitenfehlerrate
Wenn ein Prozess alle benötigten Seiten im Hauptspeicher hat, wird er keine Seitenfehler verursachen. Je weniger benötigte Seiten im Hauptspeicher sind, desto öfter generiert ein Prozess einen Seitenfehler. Eine Seitenfehlerrate ist der Anteil der Seitenfehler pro Zugriff.

Lokales Verhalten
Lokalität ist eine Eigenschaft eines Programms. Ein Programm mit lokalem Verhalten kann z.B. schneller ausgeführt werden. Diese Eigenschaft kann bei der Programmierung beeinflusst werden.
Beispiel: Bei der Seitengröße 4 KB und N=1024, benötigt das Programm ca. 1024 Seiten: N*N*sizeof(int).
int a[N][N];
void schnell() {
for(int i=0; i<N; i++)
for(int j=0; j<N; j++)
a[i][j]=0;
}
int a[N][N];
void langsam() {
for(int i=0; i<N; i++)
for(int j=0; j<N; j++)
a[j][i]=0;
}
void schnell() {
for(int i=0; i<N; i++)
for(int j=0; j<N; j++)
a[i][j]=0;
}
int a[N][N];
void langsam() {
for(int i=0; i<N; i++)
for(int j=0; j<N; j++)
a[j][i]=0;
}
Links 1024 Seitenanforderungen, rechts 1024*1024 !
⇒ Demo 4
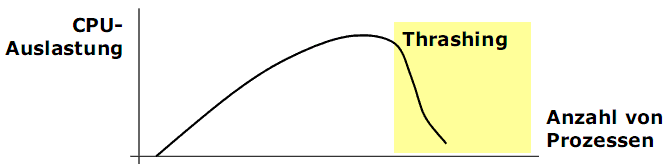
Thrashing
Definition:
Thrashing (Dreschen, Seitenflattern) ist ein Betriebszustand, bei dem
1) Prozesse nicht genug Speicherplatz besitzen und
2) ein sehr intensiver Seitenwechsel stattfindet, z.B. bei jedem Speicherzugriff, so dass
3) das System keine produktive Arbeit mehr leistet.
Eigenschaften:
1) CPU wird nicht belastet,
2) Festplattenaktivität ist enorm.
Analogie: Leeres Stroh dreschen.
Mögliche Ursachen:
1) kein lokales Verhalten von Prozessen,
2) nicht genügend Hauptspeicher,
3) zu hoher Grad an Mehrprogrammbetrieb,
4) ungünstige Ersetzungsstrategie.
⇒ Demo 5
Thrashing und Multitasking
1) Wenn die Anzahl von Prozessen im Hauptspeicher zu hoch ist, dann hat jeder Prozess nur eine geringe Anzahl seiner Seiten
verfügbar.
2) Unmittelbar nach dem ein Prozess den Prozessor bekommt, verursacht er deshalb einen Seitenfehler und wird blockiert.
3) Erst ausgelagerte Seiten werden sofort wieder eingelagert.
4) Fast alle Prozesse verhalten sich so, kommt es zum Thrashing.
7.9. Ersetzungsstrategien
Ziele:
Wenn der Hauptspeicher zu knapp wird, muss eine oder mehrere Opferseiten entfernt (ersetzt, ausgelagert) werden, um Platz zu schaffen. Es gibt verschiedene Strategien (Algorithmen) für die Auswahl der Opferseite.
1) Ein Ziel der Ersetzungsstrategien ist, die Anzahl der Seitenfehler zu minimieren. Wenn eine vielbenutzte Seite aus dem Hauptspeicher entfernt wird, muss die wahrscheinlich sehr bald wieder eingelagert werden.
2) Ein anderes Ziel ist, die Zeit der Seitenersetzung zu minimieren. Bei der Ersetzung muss die modifizierte Seite wirklich ausgelagert werden. Das Zurückschreiben ist eine langsame I/O-Operation.
Das Problem der Seitenersetzung tritt auch in anderen Gebieten auf, z.B. Ersetzung von Blöcken im Cache-Speicher.
Kriterien : Aus den Zielen können einige Kriterien abgeleitet werden:
1) Zugehörigkeit der Seite zum aktiven Prozess.
2) Das Alter der Seite im Hauptspeicher.
3) Die Anzahl der Referenzen auf die Seite.
4) Unversehrtheit der Seite.
Hardware-Unterstützung
Es gibt zwei Statusbits, die es erlauben, nützliche Statistiken darüber aufzustellen, welche Seiten benutzt werden. Diese Bits sind ein Teil des Seitentabelleneintrags. Beide werden von der Hardware gesetzt und können vom Betriebssystem auf 0 zurückgesetzt werden.
1) Das M-Bit wird gesetzt, wenn in die Seite geschrieben wird, d.h. wenn die Seiten modifiziert wird.
2) Das R-Bit (Referenced-Bit) wird gesetzt, wenn auf die Seite zugegriffen wird (Lese- oder Schreibezugriffe).
Einige Ersetzungsstrategien verwenden einen Zeitstempel:
1) Jeder Eintrag in der Seitentabelle hat einen Platz für den Zeitstempel.
2) In diesem Platz kann die aktuelle Zeit bei jedem Speicherzugriff hardwaremäßig gespeichert werden.
3) Je nach der Strategie kann den Zeitstempel z.B. als die Zeit der letzten Nutzung oder der letzten Einlagerung benutzt werden.

Globale und lokale Strategien
Lokale Strategien führen die Seitenersetzung für jeden Prozess isoliert durch. Für globale Strategien spielt keine Rolle, zu welchem Prozess die Opferseite gehört.
Globale Strategien bieten mehr Möglichkeiten der Optimierung.
Manche Strategien können als lokale oder als globale gestaltet werden.
Die optimale Strategie
Bei der optimalen Strategie (OPT) wird die Seite zuerst entfernt, die am längsten in der Zukunft nicht gebraucht wird.
Nachteil:
Das einzige Problem ist, dass diese Strategie nicht realisierbar ist, weil das Betriebssystem über das zukünftige Verhalten der Prozesse nicht weiß.
Vorteil:
Sie eignet sich zum Vergleich anderer realisierbaren Strategien mit der optimalen Lösung.
FIFO
Bei FIFO (First In - First Out ) wird die Seite entfernt, die schon am längsten im Hauptspeicher steht (älteste Seite).
Implementierungsvarianten:
- Betrachtet wird der Zeitpunkt des letzten Eintritts in den Hauptspeicher.
- Eine Datenstruktur (z.B. eine verkettete Liste der Seiten) wird verwaltet, die bei Ein- und Auslagerungen jeweils aktualisiert wird.
Nachteil:
Häufig benötigte Seiten (z.B der Code des Window-Manager) werden von FIFO regelmäßig ausgelagert, was sofort wieder zu Seitenfehlern führt.
Analogie: Regale im Supermarkt.
NRU
NRU (Not Recently Used ) wählt eine der Seiten, die in letztem Zeitintervall nicht verwendet wurde.
Alle Seiten werden nach dem Zustand der R- und M-Bits in vier Klassen aufgeteilt:
- nicht referenziert, nicht modifiziert,
- nicht referenziert, modifiziert,
- referenziert, nicht modifiziert,
- referenziert, modifiziert.
Die Klasse 2 entsteht, wenn bei einer Seite in Klasse 4 das R-Bit durch eine Timer-Unterbrechung gelöscht wird.
NRU entfernt eine zufällige Seite aus der obersten nicht leeren Klasse. Die Leistung ist nicht optimal, aber in vielen Fällen ausreichend.
Second Chance
Die Second-Chance-Strategie (SC) verbindet FIFO mit Referenzbits:
1) Nach FIFO-Strategie müsste die älteste Seite ausgelagert werden.
2) Dabei wird geprüft, ob diese Seite referenziert wurde.
3) Ist dies der Fall, wird ihr R-Bit gelöscht, die Seite am FIFO-Ende verschoben und wie eine neu geladene Seite behandelt. Damit verbleibt die Seite noch eine Weile im Hauptspeicher.
Wenn alle Seiten referenziert wurden, degeneriert SC zu FIFO.
Vorteil: enorme Verbesserung gegenüber FIFO.
Clock
Diese Strategie ist eine Verbesserung von SC:
1) Alle Seiten werden in einer ringförmigen Liste in Form einer Uhr verwaltet.
2) Ein Uhrzeiger zeigt auf die älteste Seite.
3) Bei einem Seitenfehler wird zunächst die älteste Seite geprüft. Wenn das R-Bit 0 ist, wird die Seite ersetzt und der Uhrzeiger wird vorgerückt.
4)Wenn das R-Bit 1 ist, wird es gelöscht, der Uhrzeiger wird vorgerückt und die nächste Seite geprüft.
Vorteil: schneller als Second Chance.
⇒ Demo 6.
LRU
Bei LRU (Least Recently Used ) wird die am längsten nicht genutzte Seite entfernt.
Diese Strategie basiert auf der Beobachtung, dass Seiten, die schon lange unbenutzt sind, wahrscheinlich unbenutzt bleiben.
Eine mögliche Implementierung:
1) Jeder Eintrag in der Seitentabelle hat ein Platz für den Zeitstempel der letzten Nutzung.
2) Bei jedem Speicherzugriff wird die aktuelle Zeit im entsprechenden Eintrag gespeichert.
3) Bei einem Seitenfehler durchsucht das Betriebssystem die Seitentabelle nach der Seite mit dem kleinsten Zeitstempel.
Vorteil: eine gute Annäherung an OPT.
Nachteil: schwierig zu implementieren.
Referenzketten
Zur Untersuchung der Wirksamkeit und zum Vergleich von verschiedenen Strategien können konkrete Seitenzugriffssequenzen verwendet werden.
Eine Referenzkette (Referenzreihenfolge ) ist eine Folge von Seitennummern, die zeitlich hintereinander referenziert werden.
Als Vergleichskriterium kann die Anzahl der Ersetzungen für eine vorgegebene Referenzkette benutzt werden.
Im folgenden Beispiel wird die Referenzkette aus 11 Zugriffen auf 6 Seiten im Adressraum mit 8 Seiten benutzt:
2 5 6 2 1 2 5 3 2 7 2
Mit diese Referenzkette werden zwei Strategien verglichen: FIFO und LRU. Der Hauptspeicher besteht aus nur drei Seitenrahmen.
Beispiel: FIFO - Seitenersetzung
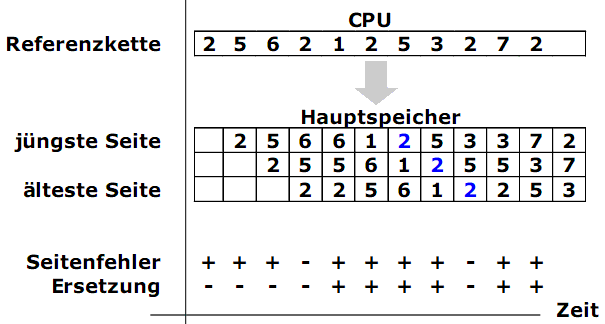
Anzahl der Ersetzungen: 6
Beispiel: LRU - Seitenersetzung
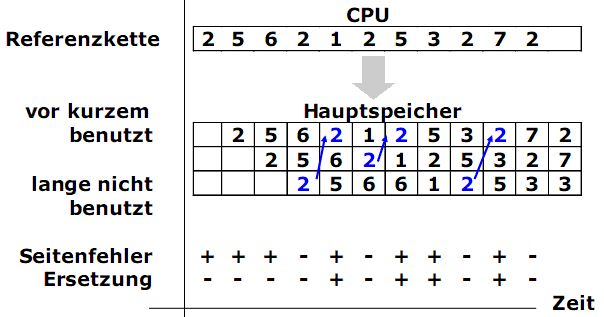
Anzahl der Ersetzungen: 4
Verwendung von Strategien
1) Windows arbeitet auf Einprozessorsystemen mit der Clock-Strategie.
Wenn ein Working-Set eines Prozesses an seine Obergrenze kommt, entfernt die Speicherverwaltung zunächst Seiten von diesem Prozess und danach erst Seiten anderer Prozesse.
2) Unix-Systeme verwenden die modifizierte Clock-Strategie.
Der Page Daemon setzt periodisch das R-Bit jeder allokierten Seite in der Seitentabelle auf 0 und wartet dann eine bestimmte Zeit. Nach dieser Zeit kann er alle Seiten auslagern, bei denen das R-Bit immer noch auf 0 ist.
CategoryBSys