
Version [22473]
Dies ist eine alte Version von BSys06Scheduling erstellt von RonnyGertler am 2013-03-26 20:20:27.
Betriebssysteme (Betriebssystemtheorie) - Kapitel 6 - Scheduling
Inhalte von Dr. E. Nadobnyh
6.1. Grundbegriffe
Definition und Eigenschaften
Der Scheduler ist ein Teil des Betriebssystems, welcher über die Prozessorzuteilung entscheidet.
1) Der Scheduler wählt einen Prozess bzw. Thread aus der Menge der ausführbaren (rechenwillige) Prozesse bzw. Threads aus, welcher als nächster den Prozessor (CPU) zugeteilt erhält. Weiter wird der Begriff „Prozesse“ statt „Prozesse bzw. Threads“ verwendet.
2) Das Scheduling (CPU-Scheduling, Prozessorverwaltung) ist die Erstellung eines Zeitplanes.
3) Das Betriebssystem selbst unterliegt nicht dem Scheduling, da es kein Prozess ist.
4) Wir begrenzen uns auf das CPU-Scheduling für das Einprozessorsystem (Uniprozessor-Scheduling).
Grundverfahren
1) Das präemptive (preemptive, verdrängende) Scheduling:
- Die CPU kann einem Prozess entzogen werden, obwohl der Prozess die CPU weiterhin verwenden möchte. Der suspendierte Prozess wird in Zustand „rechenbereit“ zurückgestellt.
b )Ursachen der Verdrängung:
- Ablauf von Zeitscheiben,
- Prozess höherer Priorität wird rechenbereit.
- Dieses Verfahren ist geeignet für Dialog- und Realtime-Systeme.
- Der aktive Prozess verwendet die CPU so lange wie er möchte.
- Dieses Verfahren ist geeignet für Batch–Systeme.
- Es ist nur ein geringer Verwaltungsaufwand nötig.
Verhungern
Es gibt einige Ursachen für das Verhungern (Starvation):
1) Wegen der ungeschickten Synchronisation: Alle Prozesse laufen uneingeschränkt weiter, aber keine Fortschritte machen.
2) Wegen des ungeschickten Schedulings: Ein rechenwilliger Prozess kann nie die CPU zugeteilt bekommen, weil die CPU von anderen Prozessen monopolisiert ist.
Beispiel für präemptives Schduling: ein Prozess mit niedriger Priorität kann ewig auf CPU-Zuteilung warten, da ständig hochprioritäre Prozesse die CPU anfordern.
Beispiel für nicht-präemptives Schduling: ein "unkooperativer" oder fehlerhafter Prozess kann die CPU monopolisieren, z.B. wenn ein fehlerhafter Prozess eine endlose Schleife beginnt.
⇒ Demo 1
Unterbrechung und Verdrängung
1) Das Betriebssystem übernimmt die Kontrolle über dem Rechner bei jeder Unterbrechung.
2) Nicht bei jeder Unterbrechung wird das Scheduling eingeschaltet. Beispiele:
- nach der Unterbrechung wegen einer fehlerhaften I/O-Operation ändern sich die Prozess-Zustände nicht und der unterbrochene Prozess bleibt weiter aktiv.
- Ähnlich reagiert das Betriebssystem auf Unterbrechungen vom Timer. Das Scheduling wird nur zu jeder k-ten Timer-Unterbrechung eingeschaltet, wenn eine Zeitscheibe abläuft.
3) Nicht bei jeder Einschaltung des präemptiven Schedulings wird über eine Verdrängung entschieden.
Begriffsverwirrung: „preemptiv“ kann manchmal als „unterbrechend“ übersetzt werden.
Zeitpunkte für neues Scheduling
1) Erzeugung eines neuen Prozesses.
2) Beendigung eines Prozesses.
3) Blockierung des bis dahin aktiven Prozesses, z.B. wenn ein Prozess eine E/A-Operation beauftragt hat und auf das Ergebnis warten muss.
4) Deblockierung des Prozesses, weil er einen Ereignis erhalten hat, z.B. weil die beauftragte E/A-Operation beendet hat.
5) Ablauf der für aktiven Prozess zugeteilten Zeit und Verdrängung des aktiven Prozesses.
Wegen der Erzeugung oder der Deblockierung eines hochprioritären Prozesses kann der aktive Prozess verdrängt werden.
Warteschlangen im Betriebssystem
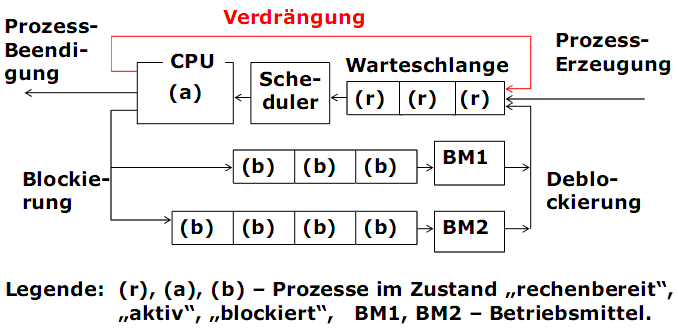
6.2. Scheduling-Kriterien
Scheduler-Aufgaben
1) Die Aufgabe eines Schedulers ist die optimale CPU-Zuteilung.
2) Für die Lösung wurden eine Vielzahl von Scheduling-Algorithmen (Scheduling-Strategien) erfunden. Diese Vielzahl kommt daher, dass je nach Ziel unterschiedliche Lösungen optimal sind.
3) Es gibt auch viele Ziele (Kriterien, Anforderungen), die für verschiedene Betriebsarten (Stapel, Dialog, Echtzeit) definiert wurden.
4) Ziele sind widersprüchlich, z.B. Effizienz zu Antwortzeit.
5) Es gibt keinen idealen Scheduling-Algorithmus, der alle Scheduling-Ziele erfüllt.
6) Scheduler kann in einem System mehrere Betriebsarten, z.B. Stapel- und Dialogbetrieb, unabhängig voneinander optimieren.
Einige Scheduling-Kriterien
Gerechtigkeit (Fairness): Jeder Prozess erhält einen gerechten CPU-Anteil.
Effizienz: Die Auslastung der CPU und der übrigen Systemkomponenten soll erhöht werden, möglichst zu 100%.
Durchsatz: Abarbeitung möglichst vieler Aufträge pro Zeiteinheit.
Terminerfüllung: Bereitstellung bestimmter Ergebnisse zu festgelegten Terminen.
Antwortzeit: Die Zeit zwischen einer Eingabe und der Reaktion darauf in interaktiven Systemen soll minimiert und in Echtzeitsystemen garantiert werden.
Durchlaufzeit
Ein der Scheduling-Kriterien ist die Durchlaufzeit, die im Stapelbetrieb verwendet wird. Die durchschnittliche Durchlaufzeit soll minimiert werden.
Die Durchlaufzeit (Verweilzeit) ist die gesamte Zeit, in der sich ein Prozess im System befindet.
Die Durchlaufzeit ergibt sich aus der Summe: Durchlaufzeit = Bedienzeit + Wartezeit.
Eine Wartezeit ist die Summe aller Zeiten in allen Warteschlangen (auch in Bereitwarteschlange), in denen ein Prozess auf die Ausführung warten muss.
Eine Bedienzeit (Servicezeit) ist die Zeit, in der ein Prozess die CPU hält.
Manchmal werden zwei Begriffe: Antwortzeit und Durchlaufzeit als Synonyme verwendet.
6.3. Scheduling-Algorithmen
Klassifikation
Scheduling-Algorithmen können unterschiedlich klassifiziert werden, z.B. nach ihren Eigenschaften oder nach der Betriebsart, in der sie verwenden werden:
1) Kooperatives und präemptives Scheduling.
2) Prioritätsscheduling und Scheduling ohne Prioritäten.
3) Schduling in Batch-, Dialog- und Realtime- Systemen.
Ein Betriebssystem kann in der Regel eine Kombination von Scheduling-Algorithmen verwenden.
Klassische Scheduling-Algorithmen: FIFO, SJF und RR gehören zu dem Scheduling ohne Prioritäten.
FIFO –Algorithmus
Definition: FIFO (First In First Out, FCFS -First Come First Serve) bearbeitet die Aufträge in der Reihenfolge ihres Eintreffens.
Eigenschaften:
1) Es findet keine Verdrängung des aktiven Prozesses statt.
2) Ein Prozess, der nach Blockierung wieder rechenbereit ist, kommt an das Ende der Warteschlange.
Vorteile:
1) Keine Gefahr wegen Verhungern.
2) Geringe Verluste durch Prozesswechsel.
3) Einfache Implementierung.
Nachteil:
Convoy–Effect bedeutet, dass ein langer Prozess viele kurze Prozesse verzögern kann.
SJF – Algorithmus
Definition:
SJF (Shortest Job First, SPF-Shortest Process First, SPN-Shortest Process Next) wählt den Auftrag mit der kürzesten Bedienzeit aus.
Eigenschaften:
- SJF ist nicht präemptiv.
- Ein rechenbereiter Prozess wird in der Warteschlange nach seiner Bedienzeit geordnet.
Vorteil:
SJF ist die optimale Strategie.
Nachteile:
- Durch SJF kann ein langer Prozess verhungern, wenn vor seinem Start ständig neue kurze Prozesse kommen.
- Die Rechenzeit eines Prozesses muss im Voraus bekannt sein. Eine bekannte Rechenzeit haben diejenigen Aufgaben, welche regelmäßig ausgeführt werden müssen, z.B. Lohnrechnung, Genomanalyse, Wettersimulation.
RR –Algorithmus
Definition:
RR (Round Robin) ordnet die CPU zyklisch nacheinander allen rechenbereiten Prozessen für eine bestimmte Zeitscheibe (Quantum, Zeitspanne, Timeslice) zu.
Eigenschaften:
- Der RR-Algorithmus ist präemptiv. Neuzuteilungen finden statt, wenn:
- der aktive Prozess die CPU freigibt, z.B. durch den I/O-Systemaufruf, oder
- der aktive Prozess verdrängt wird, weil sein Quantum erschöpft ist.
- Der verdrängte (suspendierte) Prozess wird an das Ende der Warteschlange gehängt.
- Der aktive Prozess kann manchmal unterbrochen werden, aber nicht bei jeder Unterbrechung verdrängt werden, wenn sein Quantum noch nicht erschöpft ist.
Vorteil:
gleichmäßige CPU-Zuteilung.
Nachteil:
erhöhte Verluste durch Prozesswechsel.
Quantum-Größe
1) Wenn das Quantum sehr groß gewählt wird, degeneriert RR zu FIFO. Das führt zu Verzögerungen von kurzen Prozessen.
2) Ein kleines Quantum ohne Berücksichtigung der Kontextwechselzeit gewährleistet das kontinuierliche Timesharing. Jeder Prozess erhält 1/n Prozessorleistung, wo n Anzahl der Prozesse ist.
3) Ein zu kurzes Quantum erhöht die Verluste (Overhead) durch Kontextwechsel. Wenn z.B. ein Quantum 10ms lang ist und ein Kontextwechsel 1ms dauert, dann würden 10% der Rechenleistung nur für der Kontextwechsel benötigt.
4) Wird das Quantum sehr klein gewählt, leistet der Rechner keine produktive Arbeit mehr, sondern ist nur mit Scheduling und Kontextwechsel beschäftigt.
5) Übliche Größen für Quanten sind heute von 10 bis 100 ms.
Verwendung
1) FIFO hat Einfachste Implementierung und wird in allen Betriebsarten als Basisteil für moderne Scheduling- Algorithmen verwendet.
2) SJF leistet kürzeste mittlere Durchlaufzeit und ist für Stapel-Systeme gut geeignet.
3) RR hat höchstmögliche Interaktivität und ist für Dailog- Systeme gut geeignet.
4) RR und FIFO werden im Prioritäts-Scheduling kombiniert.
⇒ Demo 2.
6.4. Prioritäts-Scheduling
Priorität
Beim Prioritäts-Scheduling (PS, HPF -Highest Priority First) wird jedem Prozess eine Priorität (Vorrang) zugewiesen.
Der Scheduler wählt immer einen Prozess mit höchster Priorität aus.
Eine Priorität ist ein Zahlenwert. Ob eine hohe Zahl einer hohen Priorität entspricht oder umgekehrt, ist eine Implementierungsfrage.
|
System Priorität |
Unix | Windows | Java |
| höchste | 0 | 31 | 10 |
| niedrigste | 255 | 0 | 1 |
Eine Priorität kann durch interne oder externe Faktoren festgelegt werden:
1) Interne Faktoren legt das System fest, z.B.: Anzahl der benötigten oder schon zugeteilten Betriebsmittel.
2) Externe Faktoren legt der Benutzer fest, z.B.: Dringlichkeit, Wichtigkeit.
Die Prioritäten können mittels der Systemaufrufe festgelegt und geändert werden, z.B.:
| System | Aufruf |
| Windows | SetPriorityClass(...); |
| Unix | nice(...); |
| Java | setPriority(...); |
Grundformen des Prioritäts-Schedulings
1) Die Zuteilung der Prioritäten kann
- statisch (von der Laufzeit entkoppelt ) oder
- dynamisch (zur Laufzeit) erfolgen.
2) Die rechenbereiten Prozesse sind in einer oder mehreren Warteschlangen je nach Priorität bzw. Prioritätsstufe geordnet. In einer Prioritätsstufe gilt sekundär das FIFO- Prinzip.
Beispiele mit mehreren Warteschlangen sind:
- Prioritätsklassen,
- Feedback-Scheduling.
3) Es gibt verdrängende und nicht-verdrängende Varianten: beim (nicht) verdrängenden Prioritäts-Scheduling wird der Prozessor (nicht) immer vom rechenbereiten Prozess mit der höchsten Priorität besetzt.
Statische Prioritäten
1) Definition: Statische Prioritäten sind bereits vor dem Start des Prozesses bekannt und unveränderbar.
2) Verwendung: Sie sind in Echtzeitsystemen geeignet, um die Vorhersagbarkeit von Reaktionszeiten zu garantieren.
3) Besonderheit: Falls die Prioritäten nicht ab und zu angepasst werden, können niedrigprioritäre Prozesse verhungern.
Beispiel mit Windows
1) Ein Vordergrundprozess ist ein Prozess, dessen Fenster den Fokus hat.
2) Zur Bevorzugung von Vordergrundprozessen erhalten diese ein größeres Quantum.
3) Die Quantum-Grösse kann vom Benutzer konfiguriert werden:
| Veränderung der Systemleistung | Vordergrund-Quantum (Qv) | Hintergrund- Quantum (Qh) |
| als Workstation | 60ms | 20ms |
| als Server | 120ms | 120ms |
⇒ Demo 3
Dynamische Prioritäten
Die Priorität eines Prozesses kann entsprechend seiner Aktivitäten vom Scheduler zur Laufzeit verändert werden.
Dynamische Prioritäten werden verwendet:
1) um typische Betriebsziele (hohe Auslastung der Ressourcen bzw. hoher Durchsatz) zu befördern,
2) um niedrigprioritäre Prozesse nicht verhungern zu lassen,
3) falls Verhaltensprofil der Prozesse nicht vorhersagbar ist.
Prozessverhalten als Priorität
Definitionen:
1) CPU-lastige Prozesse (berechnungslastige Prozesse) benötigen viel CPU-Zeit und warten selten auf die Ein-/Ausgabe.
2) I/O-lastige Prozesse. Sie rechnen wenig, warten hauptsächlich auf Ein-/Ausgabe.
Verwendung:
1) Einem rechenbereiten I/O-lastigen Prozess sollte sehr schnell die CPU zugeteilt werden.
2) Nach kurzer CPU-Belegung wird der Prozess die E/A-Anforderung durchführen und die CPU wieder freigeben.
3) Die CPU kann dann einem anderen Prozess zugeteilt werden.
4) Dadurch werden sowohl die CPU als auch die Geräte besser ausgelastet.
Fazit:
Beim Scheduling sind I/O-lastige Prozesse immer wichtiger.
Problem:
Wie soll der Scheduler erfahren, welches Verhalten ein rechenbereiter Prozess hat?
Beispiele:
- Aging (Alterung) in Unix.
a) Priorität von CPU-lastigen Prozessen wird verringert,
b) Priorität für lange wartenden Prozesse wird erhöht.
- Priority Elevation in Windows:
a) Die Erhöhung der Priorität nach Erledigung von I/O,
b) das System gibt verhungernden Prozessen einen extra Schub (burst, Quantum Stretching).
6.5. Multi-Level-Scheduling
Prioritätsklassen
Definition:
1) Prioritätsklassen (Prioritäts-Ebenen, ML-Strategie, Multi-Level-Scheduling, Multilevel Queues) unterstützen verschiedene Betriebsarten in einem System.
2) Prozesse mit der gleichen Priorität werden in einer Prioritätsklasse verwaltet.
3) Jede Klasse besitzt ihre eigenen Warteschlangen und verwaltet diese nach einem eigenen Algorithmus.
4) Alle Klassen sind nach Klassenprioritäten angeordnet.
5) Der Scheduler wählt aus der obersten nicht leeren Warteschlange aus.
Prinzipbeispiel:
| Klassenpriorität | Prioritätsklassen | Strategie |
| höchste | Systemprozesse | FIFO |
| hohe | Echtzeitprozesse (Multimedia) | Prioritäten |
| normale | Interaktive Prozesse (Vordergrundprozesse) | RR |
| niedrige | Rechenintensive Stapelprozesse (Hintergrundprozesse.) | FIFO |
CategoryBSys