Version [91602]
Dies ist eine alte Version von TutoriumDokumentwortanalyseHaeufigkeitsanalyseSS18 erstellt von SebastianPrang am 2018-10-01 13:50:36.
Tutorium: Dokumentwortanalyse/Häufigkeitsanalyse
1. Tutoren:
Sebastian Prang
2. Ziel des Tutoriums:
- Verständnisgewinnung über "Bag of Words" Methode
- Worthäufigkeitanalyse an Dokumenten durchführen
- praktische Verwendung der Bag of Words Methode zur Klassifizierung von Dokumenten
3. Adressaten des Lehrangebotes:
4. Teilnahme:
5. Veranstaltungsdatum/-zeit/-ort:
6. Veranstaltungsinhalte:
- Theoretische Einführung in Bag of Words
- Praktische Vorstellung der Umsetzung in Matlab
7. Literaturhinweise:
8. Aufgaben:
- Grundlagen der "Bag of Words" Methode
- Vokabularerstellung
- Zählung auftretender Wörter
- Erklärung n-gram-model
- Bereinigung der Dokumente
- praktische Umsetzung in Matlab (Voraussetzung: Matlab2017b oder höher)
- Einlesen eines Dokuments
- Bereinigung und Filterung störender Zeichen und Stopwörter
- Erstellung von n-gram-models
- Visuelle Ausgabe des "Bag of Words"
Worthäufigkeiten mit Bag of Words
Theorie
Sinn der Worthäufigkeitsanalyse
- Klassifizierung von Dokumenten
- Dokumente in Kategorien einteilen
- Schwerpunkte herausfinden
Bag of Words
- Methode zur Merkmalsextraktion
- relativ einfaches Konzept
- Auflistung und Zählung auftretender Wörter in einem Dokument
- Erstellung des Vokabulars
- Vektoren erstellen
- Grammatik analysieren
Vokabular erstellen
- „Mobile Computing beschäftigt sich mit mobile Applications.“
- „Mobile Computing gehört zu Informatik.“
- „Informatik beschäftigt sich mit Programmieren.“
- -> voc = {„Mobile“,
„Computing“,
„beschäftigt“,
„sich“,
„mit“,
„Applications“,
„gehört“,
„zu“,
„Informatik“,
„Programmieren“}
Präsenz der Worte
- „Mobile Computing gehört zu Informatik.“
- „Mobile“ = 1, „Computing“ = 1, „beschäftigt“ = 0, „sich“ = 0, „mit“ = 0, „Applications“ = 0, „gehört“ = 1, „zu“ = 1, „Informatik“ = 1, „Programmieren“ = 0
- isVoc = [1, 1, 0, 0, 0, 1, 1, 1, 0]
Anzahl der Worte
- „Mobile Computing beschäftigt sich mit mobile Applications.“
- „Mobile Computing gehört zu Informatik.“
- „Informatik beschäftigt sich mit Programmieren.“
- voc = {„Mobile“:3, „Computing“:2, „beschäftigt“:2, „sich“:2, „mit“:2, „Applications“:1, „gehört“:1, „zu“:1, „Informatik“:2, „Programmieren“:1};
n – gram – Modell
- dient zur Kontextgewinnung (BoW zunächst kontextlose Aufzählung)
- Bigram: „Mobile Computing“, „Computing beschäftigt“, „beschäftigt sich“
- Trigram: „Mobile Computing beschäftigt“, „Computing beschäftigt sich“
- Generell: n-gram
n – gram – Modell Beispiel
- „Mobile Computing beschäftigt sich mit mobile Applications.“
- „Mobile Computing gehört zu Informatik.“
- bigram = {„Mobile Computing“:2, „Computing beschäftigt“:1, „beschäftigt sich“:1, „Computing gehört“:1, „gehört zu“:1}
- „Mobile Computing“ kommt öfters zusammen vor -> gehört zusammen (Bezeichnung bestehend aus zwei Worten)
Filterung des Vokabulars
- große/viele Dokumente -> großes Vokabular bzw. großer Vektor
- Reduzierung der Vektorgröße bspw. durch:
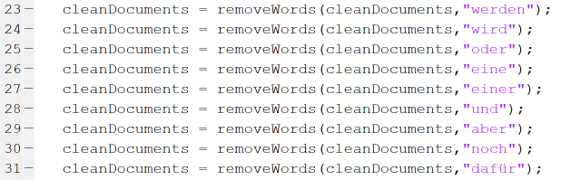
- ignorieren von „Stopp-Wörtern“ ('und', 'oder', 'doch', 'weil‘, 'an', 'in', 'von‘)
- Reduzierung auf Stammwort (gegangen, ging, geht -> gehen)
- Korrektur falsch geschriebener Wörter
Bag of Words in Matlab
- Einführung der Bag of Words Methoden: Version 2017b
- einfaches Einlesen verschiedener Dokumenttypen möglich
- Methoden zur Bereinigung der Texte bereits vorhanden
- Stopwords allerdings nur auf englisch verfügbar
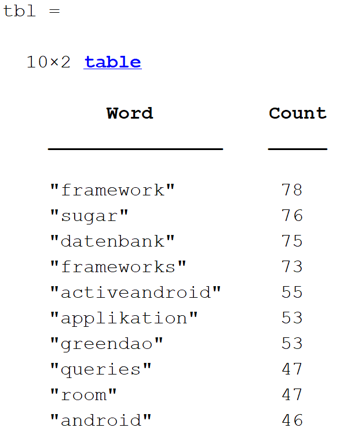
- Visuelle Darstellung des „bag“ möglich
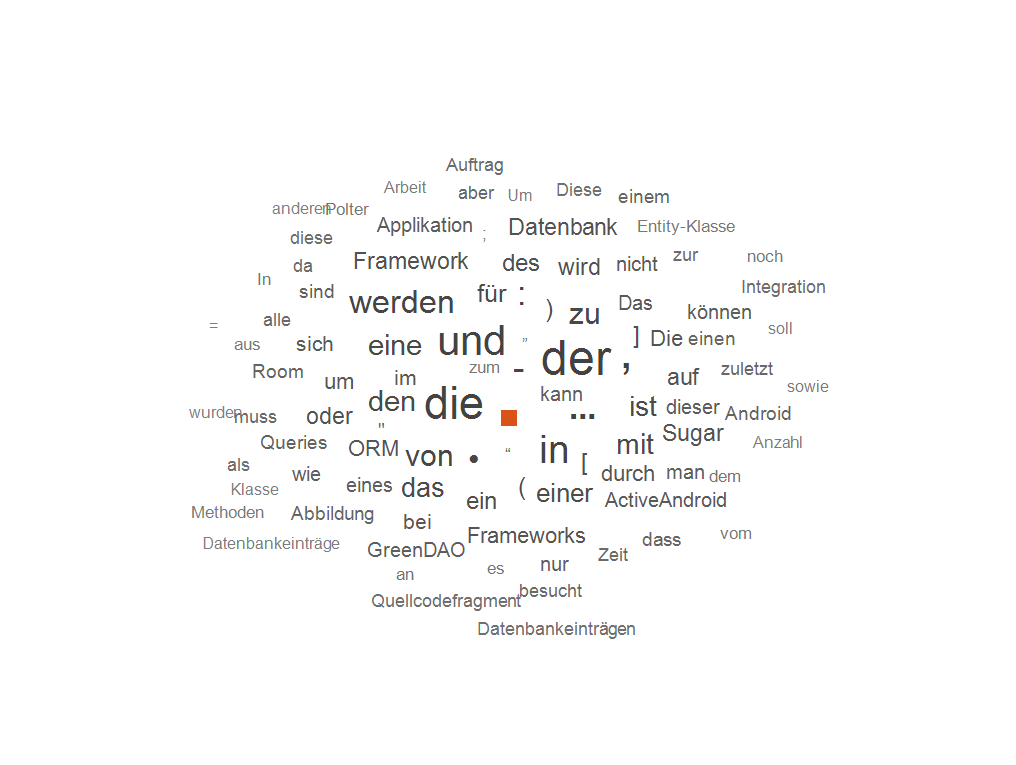
Ungefilterter Text
| File | Last modified | Size |
|---|---|---|
| Bild1.png | 2023-10-06 18:37 | 51Kb |
| Bild11.png | 2023-10-06 18:37 | 111Kb |
| Bild2.png | 2023-10-06 18:37 | 61Kb |
| Bild3.png | 2023-10-06 18:37 | 28Kb |
| Bild4.png | 2023-10-06 18:37 | 82Kb |
| Bild5.png | 2023-10-06 18:37 | 52Kb |
| Bild6.png | 2023-10-06 18:37 | 143Kb |
| Bild7.png | 2023-10-06 18:37 | 7Kb |
| Bild8.png | 2023-10-06 18:37 | 38Kb |
| Bild9.png | 2023-10-06 18:37 | 18Kb |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}