
Betriebssysteme (Betriebssystemtheorie) - Kapitel 8 - Dateisystem
Inhalte von Dr. E. Nadobnyh
8.1. Begriffsdefinition
Sekundärspeicher
Der Speicher eines Rechners ist unterteilt in Primärspeicher und Sekundärspeicher. In der Speicherhierarchie steht der Sekundärspeicher weiter vom Prozessor als Primärspeicher.
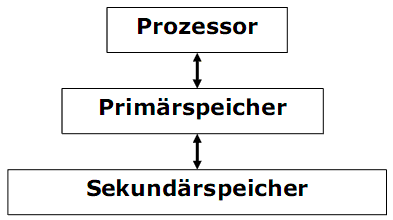
1) Der Primärspeicher (interner Speicher) ist der Hauptspeicher (Arbeitsspeicher) für aktiven Programmen, welche vom Prozessor ausgeführt werden.
2) Der Sekundärspeicher (externer Speicher) ist die dauerhafte Datenablage auf Massenspeichern.
Beispiele:
Plattenspeicher (Harddisc), Magnetbänder, CD.
Eigenschaften im Vergleich:
- Der Sekundärspeicher ist nichtflüchtig (persistent), d.h. zulässt eine dauerhafte Speicherung.
- Der Sekundärspeicher ist meist billiger, langsamer und größer als Primärspeicher.
Datei und Dateisystem
Daten in einem Sekundärspeicher werden zu Dateien zusammengefasst.
Eine Datei (file) ist ein logisches Betriebsmittel, welches eine endliche Menge zusammengehöriger Daten beinhaltet. Dateien existieren, um Daten zu speichern und später wieder abzurufen.
Ein Dateisystem (file system, Dateiverwaltung) ist ein Teil des Betriebssystems, der der Verwaltung von Daten auf einem Sekundärspeicher dient.
Alle Dateisysteme zielen auf Geräteunabhängigkeit ab, d. h ein Programm muss sich nicht darum kümmern, ob eine Datei sich auf Platte, Magnetband oder einem anderen Massenspeicher befindet.
⇒ Demo 1
8.2. Dateiattribute
Logische Organisation
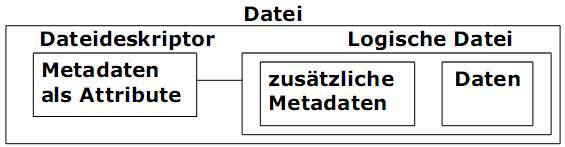
Eine Datei besteht aus zwei Teilen:
1) Eine logische Datei ist eine Einheit von Daten, die vom Dateisystem abgelagert wird. Eine physische Datei ist eine Implementierung davon und kann in mehrere Abschnitte aufgeteilt werden und sogar auf mehreren Datenträgern gespeichert werden.
2) Ein Dateideskriptor ist eine Tabelle mit Dateiattributen. Dateideskriptoren werden vom Dateisystem auf dem Datenträger abgelegt.
Dateiattribute sind dateispezifische Informationen für der Verwaltung von Dateien. Einige Dateiattribute sind;
1) Dateiname
2) Dateityp
3) Ablageort
4) Datum der Erstellung usw.
⇒ Demo 2.
Metadaten
Als Metadaten bezeichnet man allgemein Daten, die Informationen über andere Daten enthalten.
Beispiele:
- Der Name des Autors und die Auflage zu einem Buch.
- Attribute zu einer Datei.
Da im Dateideskriptor nur eingeschränkter Platz für die Attribute zur Verfügung steht, können Metadaten zusätzlich direkt in die Datei integriert werden.
Beispiel: ID3-Tags in MP3-Dateien.
Dateinamen
Eine Datei ist bei der Erzeugung zu bezeichnen. Unter ihrem Namen kann eine Datei von verschiedenen Prozessen benutzt werden.
Die Dateinamenserweiterung (filename extension, Dateierweiterung, Dateiendung, Dateisuffix) ist der letzte Teil eines Dateinamens und wird gewöhnlich mit einem Punkt abgetrennt, z.B.: „prog.c“.
Die Erweiterung ist optional und wird oft eingesetzt, um das Format einer Datei erkennbar zu machen, ohne die Datei vorher einlesen zu müssen.
⇒ Demo 3.
Dateitypen und Dateizuordnung
Ein Dateityp (Dateiformat) ist eine Definition der Syntax und Semantik von Daten innerhalb einer Datei. Die Erkennung des Formats einer Datei ist notwendig, um Datei-Inhalte richtig interpretieren zu können.
Jedes Betriebssystem muss zwei Varianten von Dateitypen unterscheiden:
1) ausführbare Programme, die in Form von Dateien (executable files) gespeichert werden. Bei der Auswahl wird dieses Programm gestartet, z.B.: „prog.exe“.
2) nicht ausführbare Dateien (Daten, Dokumente). Diese Dateien werden vom Betriebssystem nicht interpretiert, sondern Anwendungsprogrammen zugeordnet, die die Dateien interpretieren können.
Nach der Art des Inhaltes werden unterschieden:
1) Binärdateien enthalten beliebige Bytewerte (auch nicht-alphabetische Zeichen) und können in der Regel nur durch entsprechende Anwendungen gelesen werden. Dazu gehören auch ausführbare Dateien.
Beispiele: a.xls, a.exe, a.obj.
2) Textdateien (ASCII-Dateien) enthalten nur reinen Text und einfache Steuerzeichen, z.B. Zeilenumbruch. Viele Steuerdateien sind Textdateien.
Beispiele: a.htm , a.txt, a.bpr.
Dateityp-Ermittlung
Das Dateiformat kann auf drei verschiedene Arten automatisch ermittelt werden:
1) Die Ermittlung durch Dateinamenserweiterung ist häufig verwendete Methode.
Beispiel: Beim Doppelklick auf buch.doc startet Windows das zugeordnete Programm Microsoft Word mit dieser Datei als Parameter.
2) Die Ermittlung durch Dateiinhalte. Dabei wird auf bekannte Muster untersucht, z.B.: UNIX identifiziert den Dateityp durch die so genannten „magischen Zahlen“.
3) Die Ermittlung durch Metadaten ist die zuverlässigste Methode, weil das Dateiformat zusammen mit der Datei abgelegt ist.
Die Dateityp-Ermittlung durch die Dateinamenserweiterung kann als Anlockung von Würmer benutzt werden.
1) Beim Umbenennen einer Dateinamenserweiterung ändert sich schließlich nur der Dateiname, das Dateiformat bleibt dabei erhalten.
2) Bei Windows werden einige Dateinamenserweiterung standardmäßig nicht angezeigt, z.B. „.exe“.
3) Ein Benutzer kann z.B. per e-mail die ausführbare Datei „Name.jpg.exe“ erhalten, die beim Aufruf Schaden anrichten kann.
4) Der Benutzer wird so in die Irre geführt, da er den Namen „Name.jpg“ sieht und tatsächlich eine ausführbare Datei statt einer Bilddatei aktivieren kann.
⇒ Demo 4
8.3. Dateioperationen
Datei-Spezifikation
Eine Spezifikation einer logischen Datei (abstrakter Datentyp, ADT-Datei) ist eine formalisierte Beschreibung der grundlegenden Dateioperationen unabhängig vom konkreten Dateisystem.
Es wird von der tatsächlichen Implementierung der Operationen abstrahiert. Die Abbildung der logischen Datei auf reale Speichergeräte (Platte, Band, Drucker, etc.) erfolgt durch das Dateisystem.
Eine logische Datei wird vom Dateisystem wie ein langer char-Vektor behandelt:
1) Eine logische Datei ist ein Behälter für eine Reihenfolge von Bytes.
2) Der Dateiinhalt ist beliebig, da er vom Dateisystem nicht interpretiert wird.
3) Die Dateilänge ist nicht im Voraus abzusehen.
Dateiindex
Zu der Spezifikation einer logischen Datei gehört ein Dateiindex (Schreib-/Lese-Zeiger, Dateizeiger, Byte-Position, Seek-Zeiger, Zeichenposition, aktuelle Position, Dateiposition), der von Dateioperationen benutzt wird.
Alle Bytes in einer Datei sind von 0 bis N-1 durchnummeriert. in Dateiindex ist eine ganzzahlige Variable, die innerhalb einer Datei beliebig positioniert werden kann.
Dateiindex ist die Position eines Bytes, welches als Nächstes gelesen oder geschrieben wird.

Ein Dateiindex wird beim Öffnen einer Datei angelegt und beim Schließen der Datei gelöscht. Grundsätzlich gilt, dass der Dateiindex beim Lesen bzw. Schreiben entsprechend der transferierten Anzahl der Bytes in Richtung Dateiende verschoben wird.
Die Dateiendesituation (End Of File, EOF) wird festgestellt, wenn der Dateiindex das Dateiende erreicht. Beim Lesevorgang wird bei jeder Vorwärtsbewegung geprüft, ob die Dateiendesituation gerade vorliegt.
Begriffsverwirrung: Der Begriff Dateizeiger (File-Pointer) wird auch in ANSI C für die Bezeichnung eines Zeigers vom Typ FILE verwendet.
Grundlegende Dateioperationen
Unabhängig von konkreten Systemen sind folgende grundlegende Dateioperationen spezifiziert:
1. Create und Delete
- Erzeugen einer leeren Datei.
- Löschen einer vorhandenen Datei.
2. Open und Close
- Öffnen einer vorhandene Datei. Ein Dateiindex wird angelegt und positioniert.
- Schließen der Datei. Der entsprechende Dateiindex wird gelöscht.
3. Write und Read
- Schreiben in eine Datei ab einem Dateiindex.
- Lesen aus einer Datei ab einem Dateiindex.
4. Seek - Positionieren des Dateiindexes.
Öffnen und Schließen von Dateien
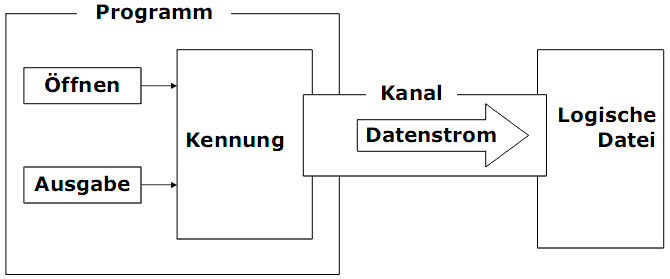
1) Beim Öffnen einer Datei wird eine Strukturvariable angelegt, die als eine Kennung (Deskriptor, Handle) bezeichnet wird. Eine Kennung enthält u.a. einen Dateiindex. Nach dem Öffnen sind die Zugriffe auf die Datei erlaubt, z.B. Lesen, Schreiben, Positionieren. Nachfolgende Dateioperationen arbeiten mit der Kennung.
Wird eine Datei mehrmals geöffnet, so wird für jedes neue Öffnen eine separate Kennung angelegt.
2) Schließen der Datei ist eine komplementäre Operation zum Öffnen. Danach wird die Kennung gelöscht und keine weiteren Zugriffe auf die Datei erlaubt.
Kanal und Datenstrom
Ein- und Ausgabe wird als Datenstrom (Byte-Strom, stream) behandelt. Streams sind immer unidirektional.
1) Beim Öffnen einer Datei wird ein Kanal (logischer Kanal, Zugriffskanal, Verbindung ) vom Prozess zur vorhandenen logischen Datei angelegt und eine Übertragungsrichtung des Kanals festgelegt:
- unidirektionaler Kanal für Ausgabe,
- unidirektionaler Kanal für Eingabe,
- bidirektionaler Kanal für abwechselnde Eingabe und Ausgabe.
2) Bei der Ausgabe wird eine Folge von Bytes durch den Kanal transportiert und in die Datei geschrieben.
3) Bei der Eingabe kann die gespeicherte Reihenfolge durch den Kanal exakt wieder abgerufen werden.
Prinzipbeispiel
Datei-Öffnen zur Ausgabe
Dateizugriffsschnittstellen
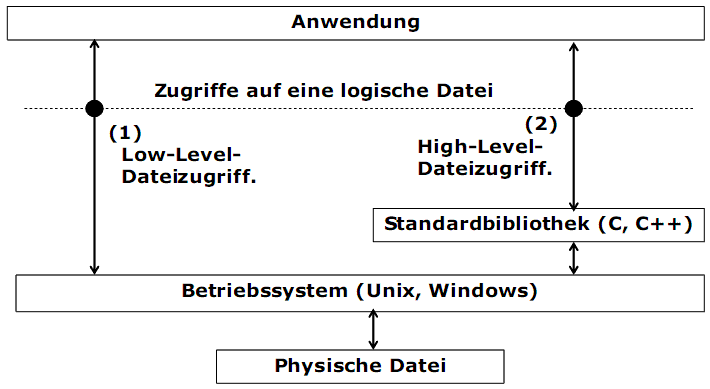
Eine Menge von Dateioperationen einer logischen Datei kann als eine Dateizugriffsschnittstelle bezeichnet werden. Die unterschiedlichen Systeme stellen konkrete Dateizugriffsschnittstellen zur Verfügung.
Zwei Abstraktionsniveaus sind bekannt:
1) Low-Level-Dateizugriff mittels der Operationen von Betriebssystemen. Diese Operationen sind hardwareunabhängig, gehören aber nicht zu dem ANSI C-Standard.
2) High-Level-Dateizugriff mittels der Operationen von Standardbibliotheken. Diese Operationen sind unabhängig von Betriebssystemen bzw. portabel.
Einige Dateioperationen
| C-Standardbibliothek (stdio.h) | Unix-Dateisystem | Windows-Dateisystem | Beschreibung |
| fopen | open /create | CreateFile | Neue Datei erzeugen |
| remove | unlink | DeleteFile | Datei löschen |
| fopen | open | CreateFile | Vorhandene Datei öffnen |
| fclose | close | CloseHandle | Datei schließen |
| fread /fwrite | read /write | ReadFile /WriteFile | Lesen von Datei und Schreiben in Datei |
| fseek | lseek | SetFilePointer | Positionieren des Dateizeigers |
| fflush | fsync | FlushFileBuffers | Sofortiges Schreiben des Puffers |
| feof | - | - | Prüft, ob Dateiende erreicht |
8.4. Einige Dateioperationen der C-Standardbibliothek
Erzeugen und Löschen von Dateien
1) Es gibt keine spezielle Funktion zum Erzeugen einer Datei. Eine Datei kann durch die Funktion „fopen“ implizit erzeugt werden. Prototyp:
FILE* fopen(char* dateiname, char* modus);
Das Argument „modus“ ist die Zugriffsart. Beim bestimmten Modus wird eine Datei mit dem „dateiname“ erzeugt, falls sie noch nicht existiert. Danach wird diese Datei sofort geöffnet.
2) Eine Datei wird durch die Funktion „remove“ gelöscht. Prototyp:
int remove(char* dateiname);
Vor dem Löschen muss die Datei geschlossen werden. Bei fehlerfreier Ausführung liefert „remove“ den Wert 0 zurück.
⇒ Demo 5.
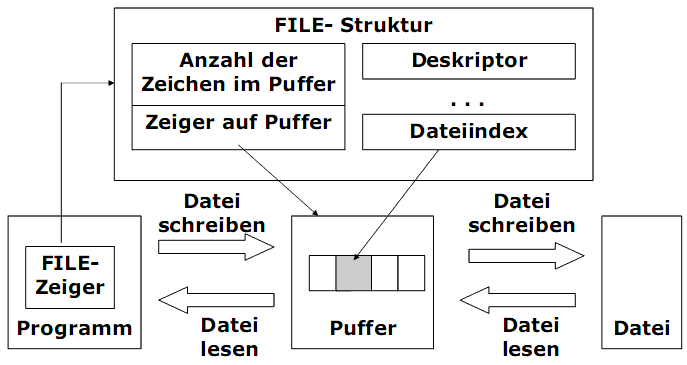
Öffnen von Dateien
FILE* fopen(char* dateiname, char* modus);
1) Betriebssystem sucht oder erzeugt die Datei mit dem „dateiname“.
2) Beim Erfolg wird eine FILE-Struktur (Kennung) erzeugt.
3) Die Eigenschaften der Datei werden in einer FILE-Struktur abgelegt, z.B.:
- ein Dateiindex wird gesetzt,
- ein programminterner Dateipuffer wird angelegt.
4) Die Adresse auf der FILE-Struktur wird zurückgegeben, die beim Dateizugriff verwendet wird.
FILE ist eine spezielle Struktur und ist in stdio.h definiert. Im Normalfall sollte der Programmierer nichts mit den Interna der FILE-Struktur zu tun haben.
High-Level-Dateizugriff
Einige Zugriffsarten beim Öffnen
| Modus | Beschreibung |
| „w“ und „w+“ (write) |
1) Datei zum Schreiben („w+“ - und zum Lesen) öffnen. 2) Existiert die Datei, wird der alte Inhalt überschrieben. 3) Datei wird erzeugt, wenn sie noch nicht existiert. |
| „a“ und „a+“ (append) |
1) Datei zum Anfügen („a+“ - und zum Lesen) öffnen. 2) Existiert die Datei, wird es am Dateiende weiter geschrieben. 3) Datei wird erzeugt, wenn sie noch nicht existiert. |
| „r“ und „r+“ (read) |
1)Datei zum Lesen („r+“ - und zum Schreiben) öffnen. 2)Datei muß existieren. |
Der Modus bestimmt auch die Dateiart:
| Modus | Dateiart | Besonderheiten |
| t oder implizit | Text-Datei | Unter Windows werden Steuerzeichen in der Datei beachtet. |
| b | Binär-Datei | Steuerzeichen werden nicht beachtet. |
Beispiele: „rt“, „wb“ , „at+“, „rb+“ usw.
Schreiben und Lesen von Dateien
Die C-Standardbibliothek bietet auch Funktionen für zeichenweisen, zeilenweisen, formatierten und blockweisen Datentransfer, während sich Unix und Windows auf den Blocktransfer beschränken.
| Daten | Zeichen | C-String | Formatierte Daten | Block |
| Schreiben | fputc | fputs | fprintf | fwrite |
| Lesen | fgetc | fgets | fscanf | fread |
Beispiel:
- fread liest aus der Datei fp in den Zwischenpuffer zp bis zu n Datenobjekte der Größe size:
int fread (void* zp, int size, int n, FILE* fp);
- fwrite ist die Gegenfunktion:
int fwrite(void* zp, int size, int n, FILE* fp);
⇒ Demo 6
Textmodus
1) Bei Windows-Compilern gibt es den Unterschied zwischen einer Datei im Text- und im Binärmodus. Im Textmodus wird:
- beim Schreiben eines Zeilenendes ein LF durch ein CR LF (Carriage Return, Line Feed) ersetzt,
2) Bei UNIX-Compilern wird der Schalter b zwar akzeptiert, es gibt jedoch keinen Unterschied zwischen Text- und Binärmodus.
Es wird auf den Ersetzungsvorgang am Zeilenende komplett verzichtet.
⇒ Demo 7
Dateipuffer
Die High-Level-Funktionen verwenden einen programminternen Dateipuffer. Die Funktionen greifen zum Lesen und Schreiben immer nur auf den Dateipuffer zu. Der Dateipuffer ermöglicht einen effektiver Datentransfer zwischen Primärspeicher und Sekundärspeicher.
Der Dateipuffer birgt jedoch das Risiko eines möglichen Datenverlustes in sich. Wenn eine Datei für die Ausgabe geöffnet wurde, werden Daten erst beschrieben, wenn der Puffer voll ist. Ist das Programm durch einen Fehler abgebrochen, gehen die Daten im Puffer verloren.
Die Funktion fflush schreibt sofort alle Daten des Ausgabestroms aus dem Dateipuffer in den Sekundärspeicher. Es wird empfohlen, nach der Ausgabe sehr wichtiger Daten die Funktion fflush aufzurufen.
Wahlfreier Dateizugriff
Der wahlfreie Dateizugriff (direkter Zugriff, random access) bietet die Möglichkeit, die Informationen direkt an einer bestimmten Position in der Datei zu lesen bzw. zu verändern.
Eine der Funktionen zur Positionierung ist:
int fseek(FILE *fp, long offset, int basis);
fseek positioniert den Dateiindex in der Datei fp auf die Position basis mit dem Abstand offset. Der Abstand kann auch negativ sein. Der Bezugspunkt basis kann einen der folgenden drei Werte haben: 0 -Dateianfang, 1 -aktuelle Position, 2– Dateiende.
Im Fehlerfall ist der Funktionswert ungleich Null.
Bemerkung:
Es gibt zusätzliche Bedingungen für die Positionierung in Textdateien.
⇒ Demo 8
8.5. Verzeichnishierarchie
Verzeichnisse
Verzeichnisse (Kataloge, Ordner, directories, directory files, Folder) sind spezielle Systemdateien, die zur Verwaltung von normalen Dateien dienen. Verzeichnisse werden für die Gruppierung logisch zusammengehöriger Dateien verwendet.
Ein Verzeichnis stellt eine Liste von Verzeichniseinträgen (directory entry) dar. Jeder Eintrag enthält:
- den Dateinamen,
- die Attribute,
- der Verweise auf den Sekundärspeicher.
In manchen Systemen können die Attribute außerhalb eines Verzeichniseintrags verwaltet werden, z.B. im I-Node. Dann enthält der Eintrag einen entsprechenden Verweis auf den I-Node.
Die interne Struktur des Verzeichnisses wird vom Anwender versteckt. Er kann auf Verzeichnisse nur mittels Systemfunktionen zugreifen.
Ein Verzeichnis kann Einträge von verschiedenen Dateiarten enthalten:
1) normale Dateien (regular files),
2) wiederum Verzeichnisse (directory file),
3) Verknüpfungen (links)
4) weitere Arten von Spezialdateien, z.B. Gerätedatei (device files).
Beispiel:
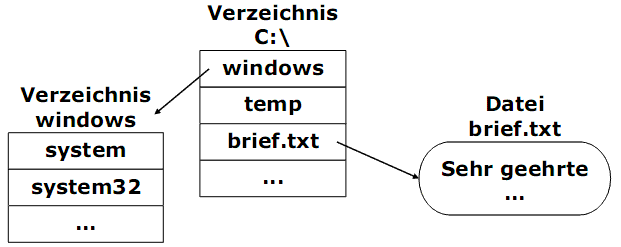
Verzeichnishierarchie
Die innere Struktur eines Verzeichnisses ist für den Aufbau der Verzeichnishierarchie geeignet. Die Hierarchie hat eine gut verständliche logische Organisation.
Es gibt zwei bekannte Arten der Hierarchie:
1) Ein Betriebssystem (z.B. UNIX) fasst alle Verzeichnisse zu einem einzigen Gesamt-Verzeichnisbaum zusammen.
2) Ein Betriebssystem (z.B. Windows) verwaltet mehrere Verzeichnisbäume (Wald).
Die externen Datenträger werden üblicherweise in Form von logischen Laufwerken betrachtet. Dabei können sich auf einem physikalischen Laufwerk mehrere logische Laufwerke befinden (Partitionierung).
⇒ Demo 9
Besondere Verzeichnisse
1) Ein Wurzelverzeichnis (root directory, Stammverzeichnis) ist das höchste Verzeichnis eines Verzeichnisbaumes. Über das Wurzelverzeichnis sind alle Dateien erreichbar.
2) Ein Unterverzeichnis (sub directory) ist jede Verzweigung eines Verzeichnisses.
3) Ein Elternverzeichnis (parent directory) ist ein im Baum übergeordnetes Verzeichnis.
Ein Arbeitsverzeichnis wurde zur Vereinfachung de Navigation im Verzeichnisbaum eingeführt. Der Benutzer (Prozess) kann jederzeit ein beliebiges Verzeichnis des gesamten Verzeichnisbaumes zum Arbeitsverzeichnis erklären.
Absoluter Pfadname
Zur Lokalisierung einer Datei dient der Pfadname, welcher aus Teilen, nämlich dem Verzeichnispfad und dem Dateinamen besteht.
Ein absoluter Pfadname ist eine Folge von Unterverzeichnissen von der Wurzel bis zur Datei. Die einzelnen Bezeichnungen werden durch einen Separator getrennt. Verschiedene Systeme verwenden unterschiedliche Separator-Formen: /, \, <.
Beispiele:
- für Unix- /home/ernie/oscar.jpg
- für Windows- C:\home\ernie\oscar.jpg
Vorteil: Es ist stets eine eindeutige Identifizierung der Datei gewährleistet.
Nachteil: Der Pfadname kann sehr lang sein.
Relativer Pfadname
Dateien können relativ zu dem Arbeitsverzeichnis adressiert werden.
Dafür wird zusätzliche Symbolik verwendet:
- Der Name ".“ verweist auf das Arbeitsverzeichnis.
- Der Name "..“ verweist auf das Elternverzeichnis.
Vorteil: Pfadnamen werden kürzer.
Nachteil: Da die Lage des Arbeitsverzeichnisses sich dynamisch ändern kann, können relative Pfadangaben zusätzliche Fehler verursachen.
Beispiele:
- absoluter Pfadname: /meier/projekt/daten/dat1
- working directory: /meier/projekt/
- relativer Pfadname: daten/dat1
Funktionen für Verzeichniszugriffe
Die unterschiedlichen Systeme stellen konkrete Verzeichniszugriffsschnittstellen zur Verfügung. Es gibt auch die portablen Verzeichniszugriffsschnittstellen, die unabhängig von Betriebssystemen sind.
Funktionen für den Zugriff auf Verzeichnisse sind im POSIX-Standard (Portable Operating System Interface) spezifiziert.
POSIX-konforme Funktionen sind vorwiegend in der UNIX-Welt beheimatet.
Auch MS-Windows-Anwender können diese Funktionen nutzen. In vielen Compilern unter diesem System sind diese Funktionen integriert.
Einige Verzeichnis-Funktionen
| UNIX, POSIX | Windows | Beschreibung |
| mkdir | CreateDirectory | Verzeichnis erzeugen |
| rmdir | RemoveDirectory | Verzeichnis löschen |
| opendir | - | Verzeichnis öffnen |
| closedir | FindClose | Verzeichnis schliessen |
| readdir | FindFirstFile | Ersten Eintrag suchen |
| readdir | FindNextFile | Nächsten Eintrag suchen |
| getcwd | GetCurrentDirectory | Arbeitsverzeichnis abfragen |
| chdir | SetCurrentDirectory | Arbeitsverzeichnis ändern |
| link, symlink | CreateHardLink CreateSymbolicLink | Dateiverknüpfung anlegen |
Es gibt keine Funktionen für das Hinzufügen oder Entfernen von Einträgen im Verzeichnis. Das erfolgt implizit beim Erzeugen und Löschen einer Datei bzw. eines Unterverzeichnisses.
⇒ Demo 10 und 11
Arbeitsverzeichnis wechseln
Während des Prozessablaufes kann sich ein Prozess beliebig in der Verzeichnishierarchie bewegen und damit sein Arbeitsverzeichnis wechseln.
Prototyp: int chdir(const char *path);
chdir (change directory) setzt das durch path bezeichnete Verzeichnis als aktuelles Arbeitsverzeichnis, z.B.:
chdir („C:\temp");
Sonderfälle:
chdir(".."); - Der Prozess bewegt sich zum Eltern-
Verzeichnis.
chdir("."); - Der Prozess bewegt sich nicht.
⇒ Demo 12
8.6. Verknüpfungen
Dateiverknüpfungen
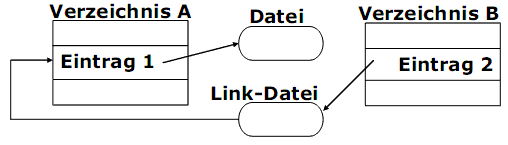
Eine Dateiverknüpfung (Verknüpfung, Link) ist eine zusätzliche Verbindung (Verweis) zwischen dem Verzeichnis und einer
normalen Datei. Damit kann eine nur einmal vorhandene Datei in verschiedenen Verzeichnissen erscheinen.
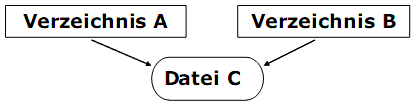
Verwendung:
1) Gemeinsame Dateien für Prozesskommunikationen. Um die Synchronisierung muss sich der Anwender selbst kümmern.
2) Gemeinsame Datei-Benutzung von mehreren Entwickler in der projektorientierten Arbeit.
3) Vermeidung von Dateikopien durch zusätzliche Verknüpfung.
4) Vereinfachung der Aktualisierung und Wartung.
⇒ Demo 13.
Verzeichnisverknüpfung
Eine Verzeichnisverknüpfung (Ordnerverknüpfung) ist eine besondere Dateiverknüpfung, die nicht auf eine Datei, sondern
auf ein Verzeichnis verweist. Damit kann ein nur einmal vorhandenes Verzeichnis in verschiedenen Verzeichnissen erscheinen.

Alle Dateien des Unterverzeichnisses sind dann auch in beiden Oberverzeichnissen erreichbar.
Hier können unerwartete Zyklen im Verzeichnisbaum entstehen. Das ist die eventuelle Ursache für endlose Schleife in naiven
Programmen.
Verknüpfungsarten
1) Harte Verknüpfungen (hard links) sind zusätzliche Verzeichniseinträge, die auf dieselbe Datei systemintern verweisen.
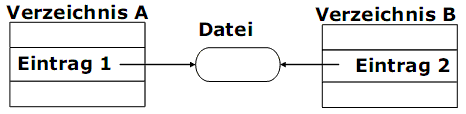
2) Weiche Verknüpfungen (symbolische Verknüpfung, soft link, symlink) sind spezielle Dateien vom Typ „link“. Eine solche Datei enthält den absoluten Pfad zur verknüpften Datei.
Eigenschaften von Verknüpfungen
1) Hardlinks sind nur innerhalb ein und desselben logischen Laufwerks möglich.
⇒ Demo 14
8.7. Dateisystemimplementierung
Einführung
Unter der Implementierung (Realisierung) versteht man Strukturen der Abbildung von Dateien und Verzeichnissen auf den Sekundärspeicher.
Bei der Sekundärspeicherverwaltung werden ähnliche Strategien verwendet, wie bei Hauptspeicherverwaltung. Die meisten Dateisysteme sind Betriebssystemspezifisch. Viele Betriebssysteme unterstützen mehr als ein Dateisystem.
Die Implementierung ist für den Anwender von geringem Interesse, obgleich sie große Bedeutung für die Entwickler eines Dateisystems darstellt.
Blockspeichermodell
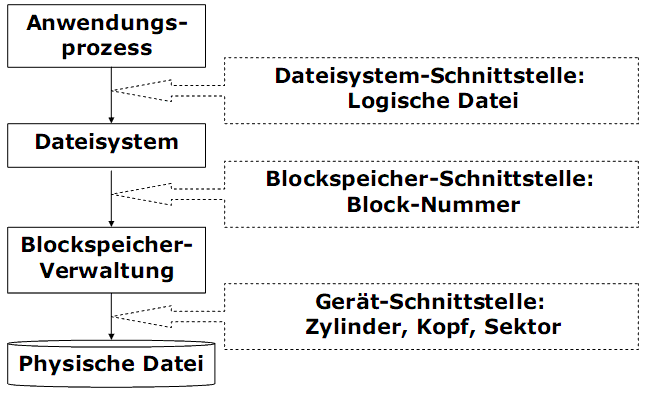
Der Sekundärspeicher ist langsamer als Primärspeicher. Aus Effizienzgründen werden Daten zwischen beiden Speicher blockweise ausgetauscht. Das Dateisystem steht auf der Blockspeicher-Schnittstelle, die systemintern ist.
Ein Datenträger stellt im Blockspeichermodell einen Behälter mit N eindeutig adressierbaren Blöcken dar.
Blöcke sind benachbart angelegt und von 0 bis N-1 durchnummeriert. Diese Nummerierung stellt die logische Blockadressierung (LBA, logical block addressing, logische Nummer) dar.

Konkret treten Blockspeicher als Wechselmedien (Diskette, CD-ROM, DVD usw.) und als Partitionen auf Festplatte auf.
Partitionen beschreiben fest abgegrenzte Teilbereiche auf Festplatten. Sie erlauben das Aufteilen eines physisches Gerät in mehrere logische Laufwerke. Je nach Rechner und Typ des Datenträgers gelten feste Vorgaben für die Blockgrößen, z.B. 0,5KB bis 32KB für Plattenspeicher und 2KB für CD-ROM.
Analog: Aufteilung des Hauptspeichers in Seiten gleicher Größe.
Datei-Abbildung
Die Abbildung einer logischen Datei in eine physische Datei erfolgt in zwei Schritten:
1) Ein Dateisystem teilt eine logische Datei in logische Blöcke auf.
2) Ein Gerätetreiber speichert logische Blöcke abhängig von der physikalischen Struktur des Gerätes, z.B. auf Festplatte als physikalische Sektoren. Die Adressierung erfolgt über die Plattenkoordinaten: Zylinder, Kopf, Sektor (Cylinder, Head, Sector).
Schichtenmodell
Aufgaben der Blockspeicherverwaltung
1) Allokation von Blöcken bei der Erzeugung einer Datei, bzw. eines Verzeichnisses und Verwaltung von zugeordneten Blöcken.
2) Freigabe von Blöcken beim Löschen einer Datei bzw. eines Verzeichnisses und "Buchführung" über freie (sowie defekte) Blöcke.
3) Realisierung und Verwaltung der Verzeichnisse und übrigen spezifischen Informationsstrukturen.
8.8. Allokationsmethoden
Definition
Eine Dateiallokation (blockweise Dateiallokation, Belegung) ist ein Verfahren zur Verfolgung, welche Blöcke des Blockspeichers mit welchen Dateien assoziiert (zugeordnet) sind.
Eine Dateiallokation ist die wahrscheinlich wichtigste Aufgabe bei der Implementierung der Dateispeicherung.
Methoden (Formen) der Dateiallokation:
- Kontinuierliche Allokation.
- Allokation durch verkettete Liste.
- Allokation durch eine Belegungstabelle.
- Allokation durch I-Nodes.
Kontinuierliche Allokation
Synonym: Zusammenhängende Belegung.
Sachverhalt:
1) Der Dateiinhalt wird in lückenlos aufeinander folgenden Blöcken gespeichert.
2) Der Verzeichniseintrag enthält die Nummer des ersten Blocks und die Anzahl der Blöcke.
Vorteil: Hohe Transfergeschwindigkeit. Die gesamte Datei kann nur mit einer Operation z.B. gelesen werden.
Nachteil: Durch das Löschen der Dateien kann eine erhebliche externe Fragmentierung des Sekundärspeichers entstehen.
Verwendungsbeispiele: Magnetband, CD-ROM, DVD.
Allokation durch verkettete Liste
Synonyme: Verweiskette innerhalb der Blöcke, Innere Verkettung, Linked List.
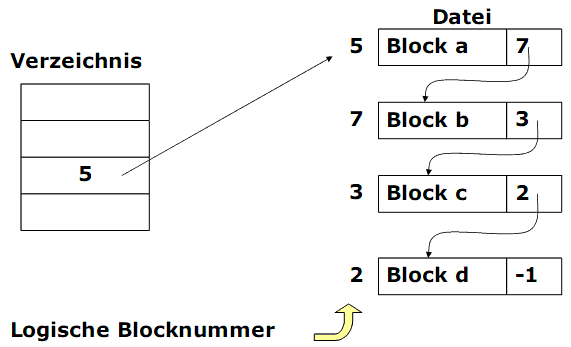
Sachverhalt:
- Jede Datei wird als verkettete Liste von Blöcken gespeichert.
- Das erste Wort eines jeden Blocks wird als Nummer des nächsten Blocks benutzt.
- Der Verzeichniseintrag enthält nur die Nummer des ersten Blocks.
Vorteile:
- Keine externe Fragmentierung.
- Bei einem defekten Verzeichnis (z.B. wegen irrtümlicher Löschung) kann die gesamte Datei wiederhergestellt werden.
Nachteil:
Der wahlfreie Zugriff ist extrem langsam. Möchte man den 123. Block lesen, so muss man alle 123 Blöcke vorher lesen.
Prinzipbeispiel
Allokation durch eine Belegungstabelle
Synonyme: Verweiskette in einer zentralen Dateibelegungstabelle, Interne Verkettung, Zentrale indexbezogene Speicherzuweisung, file allocation table.
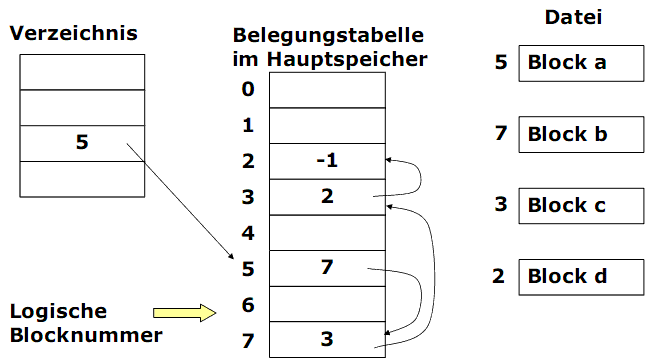
Sachverhalt:
- Im Hauptspeicher wird eine Belegungstabelle aller Blöcke verwaltet. Der Tabellenindex ist eine Blocknummer im Sekundärspeicher.
- Ein Eintrag der Tabelle ist die Nummer des Folgeblocks. Der Eintrag des letzten Blocks ist -1 (EOF, NIL).
- Das Verzeichnis enthält nur die Nummer des ersten Blocks.
- Die Belegungstabelle enthält verkettete Listen für allen Dateien (und Verzeichnisse).
- Gleichzeitig enthält sie die Übersicht über freie und defekte Sektoren. Diese sind jeweils durch spezielle Eintragswerte gekennzeichnet.
Prinzipbeispiel
Vorteile:
- Der wahlfreie Zugriff ist schnell. Die Liste einer Datei ist nicht im Sekundärspeicher verteilt, sondern liegt im Hauptspeicher.
- Keine Freiliste muss separat geführt werden.
Nachteile:
- Die gesamte Belegungstabelle muss sich zu jeder Zeit im Hauptspeicher befinden. Bei einem 20-GB –Sekundärspeicher und einer 1-KB-Blockgröße benötigt die Tabelle 20 Millionen Einträge.
- Die Tabelle wächst proportional mit der Größe des Sekundärspeicher.
Bemerkung: Diese Datenstruktur wird manchmal als eine cursorverkettete Liste bezeichnet.
Verwendungsbeispiele: FAT- Dateisystem unter MS-DOS.
Allokation durch I-Nodes
Synonyme: Verweistabelle, Indexliste, Verteilte indexbezogene Speicherzuweisung.
Sachverhalt:
- Ein I-Node (Index-Node) ist eine Datenstruktur, welche alle logische Block-Nummern einer Datei enthält.
- Ein I-Node enthält auch die Datei-Attribute.
- Für jede Datei existiert ein eigener I-Node.
Vorteile:
- Der I-Node muss nur dann im Hauptspeicher sein, wenn die Datei offen ist.
- Der Platz im Hauptspeicher wächst proportional zur Anzahl von gleichzeitig geöffneten Dateien.
Nachteil: hoher Verwaltungsaufwand.
Verwendungsbeispiel: UNIX-Dateisystem.
Prinzipbeispiel für kleine Datei
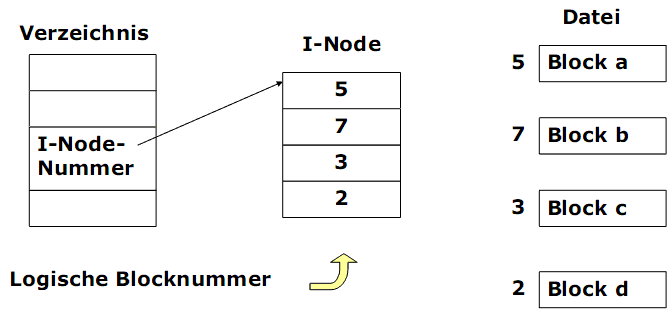
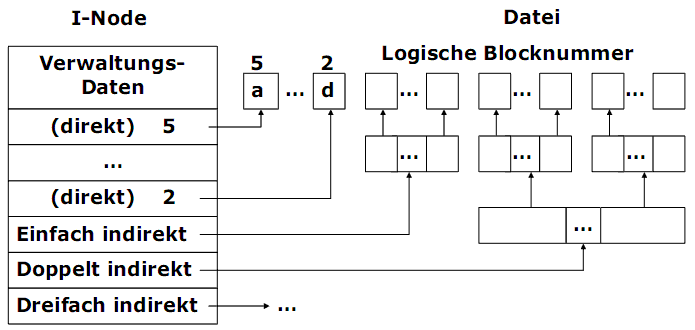
Ein I-Node besitzt ein so genanntes mehrstufiges Adressierungsschema (multilevel-index):
1) Die ersten zehn Blocknummer werden direkt im I-Node gespeichert. Für kleine Dateien sind mit der Einlagerung des I-Node alle erforderlichen Informationen im Hauptspeicher.
2) Für etwas größere Dateien enthält einer der Einträge im I-Node die Nummer des einfach indirekten Blocks. Dieser Block enthält zusätzliche Blocknummer.
3) Für große Dateien enthält ein weiterer Eintrag im I-Node die Nummer des doppelt indirekten Blocks. Dieser enthält eine Liste von einfach indirekten Blöcken.
4) Für sehr große Dateien kann auch ein dreifach indirekter Block verwendet werden.
5) Ziel: Bei kleinen und mittleren Dateien die Zahl der Blockzugriffe reduzieren.
Prinzipbeispiel für große Datei
8.9. Beispiele
Einführung
Es gibt weltweit mehr als 100 verschiedene Dateisysteme.
Einige von weltberühmten Dateisystemen sind schon spurlos verschwunden. A. Tanenbaum: „Das lässt den Gedanken aufkommen, dass Systeme, welche im Moment die Welt beherrschen, total unbekannt sein werden, wenn die Kinder der heutigen Zeit erwachsen sind.“
Zu wichtigen Eigenschaften gehören maximale Dateigröße und maximale Partitionsgröße (Limits).
FAT
FAT (File Allocation Table) ist das traditionelle Windows-Dateisystem. Es wurde für MS-DOS entwickelt.
Der MS-DOS-Verzeichniseintrag enthält u.a.:
1) die exakte Dateigröße. Da eine 32-Bit-Zahl dafür benutzt wird, kann eine Datei theoretisch 4 GB groß sein.
2) die Nummer des ersten Dateiblocks (Blocknummer).
Bemerkung: Blöcke werden bei Microsoft als Cluster bezeichnet.
Blöcke können auf verschiedene Größe gesetzt werden: von 0,5 KB (29) bis 32 KB (215).
Durch die Bitlänge der Blocknummer werden die folgenden drei Parameter begrenzt:
- die maximale Blockanzahl im Sekundärspeicher,
- die maximale Blockanzahl in der Datei,
- die maximale Anzahl der Dateien.
Abhängig von die Bitlänge der Blocknummer gibt es drei FAT-Versionen: FAT-12, FAT-16 und FAT-32. Die letzte hat i der Tat nur 28 Bit dafür. Durch die maximale Blockanzahl und die Blockgröße ergibt sich die maximale Partitionsgröße.
| Variante | FAT-12 | FAT-16 | FAT-32 |
| Bitlänge der Blocknummer | 12 | 16 | 28 |
| Maximale Blocknummer | 212=4 K | 216=64 K | 228=256 M |
| Max. Blockgröße | 4 KB (212) | 32 KB (215) | 32 KB (215) |
| Maximale Partitionsgröße | 212 * 212 =16 MB | 216 * 215 =2 GB | 228 * 215=8 TB, tatsächlich: 2 TB |
| Max. Dateigröße | 16 MB | 2 GB | 4 GB (232) |
Das FAT-12 –System funktionierte für Disketten recht gut.
Mit FAT-16 muss eine 8-GB-Platte vier Partitionen haben, welche unter Windows dem Benutzer als logische Laufwerke C:, D:, E: und F: erschienen.
UFS
UFS (Unix File System) ist das traditionelle Dateisystem, welches stark verbreitet ist.
Der UNIX-V7-Verzeichniseintrag enthält:
- den Dateiname und
- die I-Node-Nummer.
Die I-Node-Nummer besitzt 2 Byte und limitiert dadurch die Anzahl der Dateien pro Dateisystem auf 64K.
Ein UNIX-I-Node hat zehn Blocknummern und die Nummern für einfach, doppelt und dreifach indirekte Blöcke.
Wenn z.B. ein Block 1 KB groß ist und eine Blocknummer 4 Byte lang ist, so kann der Block 256 Blocknummern enthalten.
Unter dieser Annahme kann die maximale Dateilänge berechnet werden:
1) Der I-Node enthält direkt die ersten 10 Blocknummern.
2) Das einfach indirekte Block enthält 28 = 256 Nummern.
3) Das doppelt indirekte Block enthält
28 * 28 = 65 536 Nummern.
4) Das dreifach indirekte Block enthält
28 * 28 * 28 = 16 777 216 Nummern.
5) Die Blockanzahl wird berechnet als:
10 + 28 + 28 * 28 + 28 * 28 * 28 ≈ 16M
6) Die Dateilänge beträgt: 16M * 1KB = 16 GB
CategoryBSys